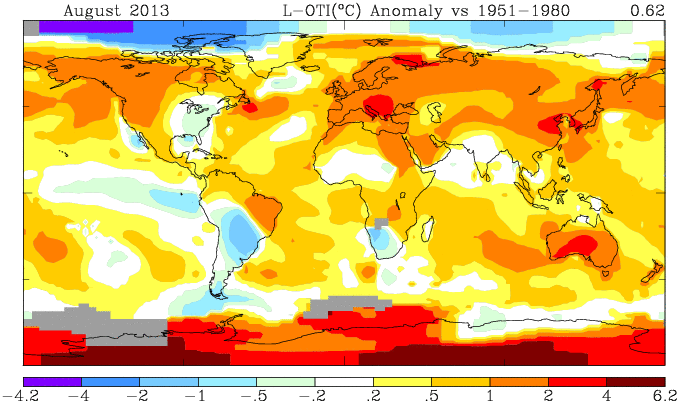
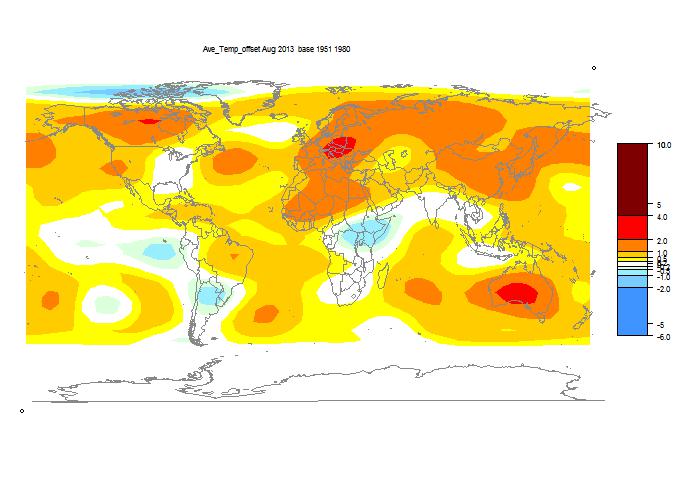
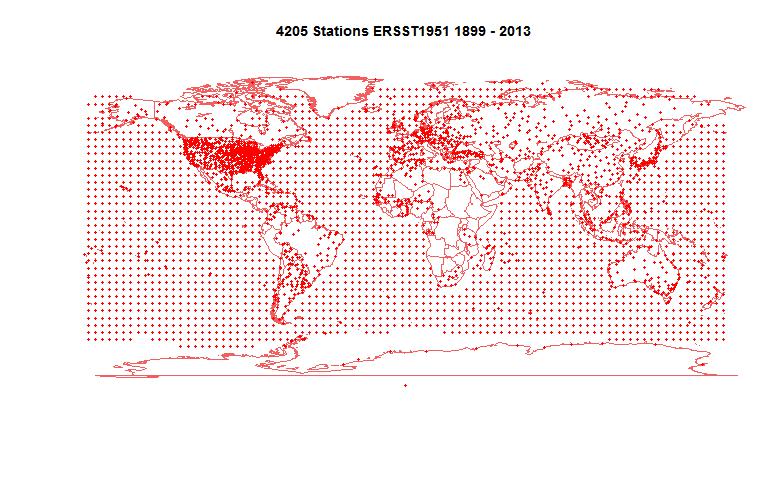
I've been writing a lot lately on autocorrelation for temperature time series. This is basically a methods post.
I've often referred to a
post by Hu McCulloch, in which he reproves a scientist for quoting just a OLS regression for a monthly series with OLS CI's, and shows how the CI's are much larger if the residuals are assumed to be not white noise but
AR(1) correlated. He gives a useful set of formulae, and describes in particular the Quenouille AR(1) correction to the trend uncertainty. This seems to be the current standard, and it is what I use in my
trend viewer.
Stats program R has an arima(xreg=) function which will give trends with error estimate for general ARIMA models. It solves a slightly different optimisation for regression, with a different trend for each ARIMA type. But for AR(1), the results are similar to the Quenouille approach.
So why bother with approximations? I'm interested for two reasons, in connection with the trend viewer. In my weekly updates, I do about 5 million regressions. That takes a bit over an hour, but only because I avoid the individual regression summations, instead using differences of cumulative sums calculated for each dataset. You can't to that in a package. arima() would take many hours.
The other reason is that to provide interactive output, I have to be able to repeat the calculation in Javascript. Time isn't an issue there, but programming simplicity is.
In this post, I'll describe some extensions which allow Quenouille style corrections to
more complex ARMA() models. I also give corrections to the OLS trend. The trend corrections are O(1/N) (N=#data) and I believe the error is then O(1/N^2), and for the CI's, O(1/N). Those errors are for the approximation to the stochastic model - whether it is the right model is a greater uncertainty.
With these formulae the complete procedure is
- Do a normal OLS regression.
- Calculate the residuals and estimate the first few autocorrelations (one lag for A(1)m 2 for AR(2) and ARMA(1,1) etc)
- Use the Yule-Walker equations to estimate the ARMA parameters. That just solves a few linear equations in the AR() parameters.
- Correct the trend and uncertainty using thge formulae given here.
Fitting stochastic models
I'm talking about fitting to regression residuals, so it is simpler to have a regression already done, although I described
a method for simultaneously fitting regression and residual model. An ARMA model for regression residuals can be written: A(L)d=M(L)ε Here A is a polynomial in the lag operator L, A=1-A1*L-A2*L^2... applied to the time series d (so L d_i = d_{i-1}) M(L) is a similar polynomial in L: M(L)=1+M1*L+... ε is a vector of iid random variables The series d is taken to be the residuals of a regression on data y: d=y-a-b*x. The notation ARMA(j,k) means that A is of order j and M of order k. The effect of applying the polynomial A to d can also be represented by the lower triangular matrix (AR(2) example) A=
| ...0 | -A2 | -A1 | 1 | 0 | 0... |
| ...0 | 0 | -A2 | -A1 | 1 | 0... |
| ...0 | 0 | 0 | -A2 | -A1 | 1... |
This is of course a fragment - if d has length n then A is (n-j) x n and is Toeplitz. M also corresponds to such a matrix. The regression equation can be written M
-1L d = ε Comprehensive programs like the R arima() will minimise d
* K
* K d where K = M
-1L over coefficients a and b, and return the appropriate uncertainties. The alternative described above is to minimise d
* d, and then adjust the coefficients and their uncertainty.
Finding and adjusting trend
The regression of the ARMA model gives trend b = y
* KK x/ x
* KK x, (KK = K
* K) assuming K x has zero mean. But KK is symmetric, and also near Toeplitz, deviating near the top left and bottom right corners. The i'th row of KK (far from corners) is symmetric about the i'th value (with unsymmetric truncation). But the arithmetic progression x can be split into a constant x
i and a part x-x
i that is antisymmetric about i. The latter yields a zero sum with that row of KK, so the result is R*x_i, where R is the (constant near centre) rowsum of KK. So KK * x ≈ R * x This argument gives b = y
* KK x/ x
* KK x ≈ y
* x/ x
* x which is the OLS value. That's why only a small adjustment is needed - it is due to end effects. In the case of AR(n) models, the deviation of KK from Toeplitz only affects the top n and bottom n rows, so it is a fairly simple matter to add up the missing terms. The corrections to the OLS trend for the various models are, for time (=x) series y of length N:
| OLS or AR(0) | b |
| AR(1) | b+(3*b+6*(y_N*A1+y_1)/(1-A1)/(x_N-x_1))/N |
| AR(2) | b+6*(b+(y_1*(1-A1)+y_2+A2*y_(N-1)+y_N*(A1+A2))/(1-A1-A2)/(x_N-x_1))/N |
And here are the results comparing these approximations with values computed with the R arima() program, setting xreg and using method="CSS".The corrected values are much closer than the OLS trend. Trends are from 1980 to July 2013.
| Data | Hadcrut4 | GISSLO | NOAA | UAH | MSU.RSS |
| OLS | 1.5643 | 1.5626 | 1.4878 | 1.4101 | 1.2979 |
| AR(1) | 1.5743 | 1.5661 | 1.4936 | 1.4257 | 1.307 |
| AR(1) approx | 1.5742 | 1.5662 | 1.4936 | 1.4257 | 1.3073 |
| AR(2) | 1.5946 | 1.5909 | 1.5072 | 1.4705 | 1.3392 |
| AR(2) approx | 1.5959 | 1.5907 | 1.5079 | 1.4696 | 1.3389 |
Trend uncertainties.
The original adjustment for AR(1) autocorrelated regression residuals was given by Quenouille (1952), and has been widely used. In an
earlier post, I gave the corresponding approximations for ARMA(1,1) and AR(2). I'll exrend to AR(3) and give the derivations here. Note that whereas for the trend we were looking for an O(1/N) adjustment, here it is O(1) - ie much bigger.
So it is sufficient to find an uncertainty adjustment for either the OLS trend or the true AR() trend. OLS is simpler.
Our ARMA model is
A(L)d=M(L)ε ε is iid
or, reverting to matrices
d=A-1M ε
The variance of the OLS trend b is then estinated by
var(b)= x*C x/x* x
where x is time (mean removed) and C is the estimated covariance of d. In the model, C=M
*A
*-1A
-1M.
Now C is symmetric, and apart from end effects, Toeplitz, reflecting stationarity. That means that each row is symmetric about the diagonal. So when the i'th row of C multiplies x, the effect of the part that is odd about x
i makes no contribution. But the even part is just the constant . So the effect of applying C to x is just to multiply by the constant rowsum of C (apart from O(1/N) end effects). The ignoring of end effects here requires that there is only moderate autocorrelation, so C is diagonally dominant.
Each row of C is just the diagonal value (zero-lag variance of d) multiplied by the acf. That diagonal value divided by x
*x. So the correction required to the variance of b is just (with our 1/N caveats) the sum of the autocovariance function.
Now it is good to go back to polynomials. The (Toeplitz) matrix product M
*M is equivalent to the polynomial M(L
-1)*M(L). And the acf is almost just the set of coefficients of the Laurent series got by expanding M(L
-1)*M(L)/(A(L
-1)*A(L)) in powers of L. A Laurent series is just a power series with both positive and negative powers.
I say almost, because the zero'th order coefficient of that series is not 1. So we have to find it and divide by it. This could be done with messy series expansion calcs, but it is neater with complex analysis, replacing L by z.
The Laurent series may converge in an annulus in the complex plane, and here it converges on the unit circle. To get the central coeficient, divide by z and integrate on that contour. It's a rational function, so that just means summing the residues inside the unit circle.
How to do that? For the previous post I did the algebra by hand, but for AR(3) I resorted to Mathematica, and I'll describe that process. I write A(z)=(1-az)(1-bz)(1-cz), so
1/A(1/z)/A(z)/z=z
2/((z-a)(z-b)(z-c)(1-az)(1-bz)(1-cz))
I don't need to ever find the roots a,b,c, and they don't have to be real. To get the residue at a, I define f(a,b,c)=a
2/((a-b)(a-c)(1-a^2)(1-ba)(1-ca))
Then I ask Mathematica to Simpliify[f[a,b,c]+f[b,c,a]+f[c,a,b]]
It comes back with a polynomial in the numerator and factors in the denominator, symmetric of course in a,b,c. The factors in the denominator I can reassemble as values of A(z) at specific points. The numerator I can recognise symmetrics like ab+bc+ca, and re-express these as coefficients of A.
Let A0 be the result - the zero'th order coefficient of 1/A(1/z)/A(z). Then the numbers in the acf are just the Laurent coefficients of 1/A(1/z)/A(z)/A0, and the sum - the Quenouille correction - is just 1/A(1)/A(1)/A0.
So here are some results. First the formulae for the Quenouille factors for adjustment of trend uncertainty:
| |
| AR(1) | (1+A1)/(1-A1)=A(-1)/A(1) |
| ARMA(1,1) | A(-1)/A(1)*(1+M1)2/(1+M12+2*M1*A1)) |
| AR(2) | A(-1)/A(1)*(1+A2)/(1-A2))) |
| AR(3) | A(-1)/A(1)*(1+A2+(A1-A3)*A32)/((1-A2-(A1+A3)*A32)) |
And here are the numerical results for the monthly data, period 1980-July 2013. First the OLS trend and standard error; then the various models, with in each case the R arima() trend and se, and then the se as calculated by the above Quenouille-style approx.
| Result | HADCRUT4 | GISS | NOAA | UAH | MSU-RSS |
| OLS trend β | 1.7020 | 1.7092 | 1.7500 | 1.4086 | 1.5676 |
| OLS s.e. β | 0.0463 | 0.0651 | 0.0514 | 0.0665 | 0.0641 |
| AR(1) trend β | 1.6984 | 1.7084 | 1.7449 | 1.4161 | 1.5678 |
| AR(1) s.e. β | 0.0785 | 0.0936 | 0.0765 | 0.1101 | 0.0978 |
| AR(1) Quen s.e. | 0.0781 | 0.0933 | 0.0762 | 0.1096 | 0.0974 |
| ARMA(1,1) trend β | 1.6953 | 1.7025 | 1.7423 | 1.4188 | 1.5687 |
| ARMA(1,1) s.e. β | 0.0946 | 0.1132 | 0.0936 | 0.1189 | 0.1027 |
| ARMA(1,1) Quen s.e. | 0.0940 | 0.1123 | 0.0930 | 0.1182 | 0.1022 |
| AR(2) trend β | 1.6854 | 1.6831 | 1.7363 | 1.4221 | 1.5756 |
| AR(2) s.e. β | 0.0929 | 0.1103 | 0.0899 | 0.1228 | 0.1045 |
| AR(2) Quen s.e. | 0.0925 | 0.1106 | 0.0894 | 0.1217 | 0.1037 |
| AR(3) trend β | 1.6893 | 1.6853 | 1.7395 | 1.4098 | 1.5673 |
| AR(3) s.e. β | 0.0908 | 0.1060 | 0.0901 | 0.1073 | 0.0971 |
| AR(3) Quen s.e. | 0.0900 | 0.1059 | 0.0893 | 0.1060 | 0.0961 |
Conclusion
For autocorrelated data, the ordinary OLS trend analysis will get the trend near right with a O(1/N) error, which can be calculated. But the standard error will be substantially underestimated. There are at least three options
- Use a package like arima() in R, which probably uses a general optimisation algorithm
- Use the Newton-Raphson-style algorithm that I described here (I'm planning an update with more systematic code). This is fast and does everything at once. It is easy to code in R, but not so much in, say, Javascript.
- Calculate and correct the OLS trends, using Yule-Walker equations to estimate model coefficients.
The approximations will deteriorate with vary high autocorrelation. Then the best remedy is to instead use, say, annual averages. Little information will be lost, and the autocorrelation will reduce.