There is an interesting article in Reason by Ron Bailey, titled "What Climate Science Tells Us About Temperature Trends" (h/t Judith Curry). It is lukewarmish, but, as it's author notes, that is movement from a more sceptical view. It covers a range of issues.
His history shows up, though, in prominence given to sceptic sources that are not necessarily in such good faith. True, he seems to reach a balance, but needs to be more sceptical of scepticism. An example is this:
"A recent example is the June 2019 claim by geologist Tony Heller, who runs the contrarian website Real Climate Science, that he had identified "yet another round of spectacular data tampering by NASA and NOAA. Cooling the past and warming the present." Heller focused particularly on the adjustments made to NASA Goddard Institute for Space Studies (GISS) global land surface temperature trends. "
He concludes that "Adjustments that overall reduce the amount of warming seen in the past suggest that climatologists are not fiddling with temperature data in order to create or exaggerate global warming" so he wasn't convinced by Heller's case. But as I noted here, that source should be completely rejected. It compares one dataset (a land average) in 2017 with something different (Ts, a land/ocean average based on land data) in 2019 and claims the difference is due to "tampering". Although I raised that at the source, no correction or retraction was ever made, and so it still pollutes the discourse.
A different kind of example is the undue prominence accorded to Christy, and Michaels and Rossiter. He does give the counter arguments, and seems to favor those counters. Since the weighting he gives to those sources probably reflects the orientation of his audience, that may in the end be a good thing, but I hope we will get to a state where these recede to their rightful place.
His conclusion is:
"Continued economic growth and technological progress would surely help future generations to handle many—even most—of the problems caused by climate change. At the same time, the speed and severity at which the earth now appears to be warming makes the wait-and-see approach increasingly risky.
Will climate change be apocalyptic? Probably not, but the possibility is not zero. So just how lucky do you feel? Frankly, after reviewing recent scientific evidence, I'm not feeling nearly as lucky as I once did."
Some might see that as still overrating his luck, but it is an article worth reading.
Saturday, November 23, 2019
Saturday, November 16, 2019
GISS October global up 0.12°C from September.
The GISS V4 land/ocean temperature anomaly stayed at 1.04°C in October, up from 0.92°C September. It compared with a 0.116deg;C rise in TempLS V4 mesh (latest figures). GISS also had 2019 as second-warmest October after 2015.
The overall pattern was similar to that in TempLS. Prominent cold spot in US W of Mississippi (and adjacent Canada). Warm just about everywhere else (but not Scandinavia).
As usual here, I will compare the GISS and earlier TempLS plots below the jump.
The overall pattern was similar to that in TempLS. Prominent cold spot in US W of Mississippi (and adjacent Canada). Warm just about everywhere else (but not Scandinavia).
As usual here, I will compare the GISS and earlier TempLS plots below the jump.
Friday, November 8, 2019
Structure and implementation of methods for averaging surface temperature.
I have been writing about various methods for calculating the average surface temperature anomaly. The mathematical task is basically surface integration of a function determined by sampling at measurement points, followed by fitting offsets to determine anomalies. I'd like to write here about the structure and implementation of those integration calculations.
The basic process for that integration is to match the data to a locally smooth function which can be integrated analytically. That function S(x) is usually expressed as a linear combination of basis functions Bᵢ(x), where x are surface coordinates
using a summation convention. This post draws on this post from last April, where I describe use of the summation convention and also processes for handling sparse matrices (most entries zero), which I'll say a lot about here. The summation convention says that when you see an index repeated, as here, it is as if there were also a summation sign over the range of that index.
The fitting process is usually least squares; minimise over coefficients b:
where the yj are the data points, say monthly temperature anomalies, at points xj) and K is some kernel matrix (positive definite, usually diagonal).
This all sounds a lot more complicated than just calculating grid averages, which is the most common technique. I'd like to fit those into this framework; there will be simplifications there.
Minimising (2) by differentiating wrt b gives
where H is the matrix Bᵢ(xj)), Hw is the matrix Bᵢ(xj))Kjk and HwH = Hw⊗H* (* is transpose and ⊗ is matrix multiplication). So Eq (4) is a conventional regression equation for the fitting coefficients b. The final step in calculating the integral as
A = bᵢaᵢ
where aᵢ are the integrals of the functions Bᵢ(x), or
The potentially big operations here are the multiplication of the data values y by the sparse matrix Hw, and then by the inverse of HwH. However, there are some simplifications. The matrix K is the identity or a diagonal matrix. For the grid method and mesh method (the early staple methods of TempLS), HwH turns out to be a diagonal matrix, so inversion is trivial. Otherwise it is positive definite, so a conjugate gradient iterative method can be used, which is in effect the direct minimisation of the quadratic in Eq (2). That requires only a series of multiplication s of vectors by HwH, so this product need not be calculated, but left as its factors.
I'll now look at the specific methods and how they appear in this framework.
The matrix H has a row for each cell and a column for each data point. It is zero except for a 1 where data point j is in cell i. The product HwH is just a diagonal matrix with a row for each cell, and the diagonal entry is the total number of data points in the cell (which may be 0). So that reduces to saying that the coefficient b for each cell is just the average of data in the cell. It is indeterminate if no data, but if such cells are omitted, the value would be unchanged if the cells were assigned the value of the average of the others.
Multiplying H by vector y is a sparse operation, which may need some care to perform efficiently.
For a long time I used SH fits, calculating the b coefficients as above, for graphic shade plots of the continuum field. But some other advanced methods provide their own fitted functions.
I described here a rather ad hoc method for iteratively estimating empty cells from neighbors with data, which worked quote well. But the matrix formulation above gives a more scientific way of doing this. You can write a matrix which expresses a requirement that each cell should have the average values of its neighbors. For example, a rectangular grid might have, for each cell, the requirement that 4 times its value - the values of the four neighbors is zero. You can make a (sparse symmetric) matrix L out of these relations, which will have the same dimension as HwH. It has a rank deficiency of 1, since any constant will satisfy it.
Now the grid method gave an HwH which was diagonal, with rows of zeroes corresponding to empty cells, preventing inversion. If you form HwH + εL, that fixes the singularity, and on solving does enforce that the empty cells have the value of the average of the neighbors, even if they are also empty. In effect, it fills with Laplace equation using known cell averages as boundaries. You can use a more exact implementation of the Laplacian than the simple average, but it won't make much difference.
There is a little more to it. I said L would be sparse symmetric, but that involves adding mirror numbers into rows where the cell averages are known. This will have the effect of smoothing, depending on how large ε is. You can make ε very small, but then that leaves the combination ill-conditioned, which slows the iterative solution process. For the purposes of integration, it doesn't hurt to allow a degree of smoothing. But you can counter it by going back and overwriting known cells with the original values.
I said above that, because HwH inversion is done by conjugate gradients, you don't need to actually create the matrix; you can just multiply vectors by the factors as needed. But because HwH is diagonal, you don't need a matrix-matrix multiplication to create HwH + εL, so it may as well be used directly.
I have gone into this in some detail because it has application beyond enhancing the grid method. But it works well in that capacity. My most recent comparisons are here.
The question of empty cells is replaced by a more complicated issue of whether each element has enough data to uniquely specify a polynomial of the nominated order. However, that does not have to be resolved, because the same remedy of adding a fraction of a Laplacian works in the same way of regularising with the Laplace smooth. It is no longer easy to just overwrite with known values to avoid smoothing where you might not have wanted it, but where you can identify coefficients added to the matrix which are not wanted, you can add the product of those with the latest version of the solution to the right hand side and iterate, removing spurious smoothing with rapid convergence. But I have found that there is usually a range of ε which gives acceptably small smoothing with adequate improvement in conditioning.
This zip contains:
LS_wt.r master file for TempLS V4.1
LS_fns.r library file for TempLS V4.1
Latest_all.rda a set of general library functions used in the code
All.rda same as a package that you can attach
Latest_all.html Documentation for library
templs.html Documentation for TempLS V4.1
The main functions used to implement the above mathematics are in Latest_all
spmul() for sparse matrix/vector multiplication and
pcg() for preconditioned conjugate gradient iteration
The basic process for that integration is to match the data to a locally smooth function which can be integrated analytically. That function S(x) is usually expressed as a linear combination of basis functions Bᵢ(x), where x are surface coordinates
| s(x) = bᵢBᵢ(x) | 1 |
The fitting process is usually least squares; minimise over coefficients b:
| (yj-bᵢBᵢ(xj)) Kjk (yₖ-bₘBₘ(xₖ)) | 2 |
where the yj are the data points, say monthly temperature anomalies, at points xj) and K is some kernel matrix (positive definite, usually diagonal).
This all sounds a lot more complicated than just calculating grid averages, which is the most common technique. I'd like to fit those into this framework; there will be simplifications there.
Minimising (2) by differentiating wrt b gives
| (yj-bᵢBᵢ(xj))KjkBₘ(xₖ) | 3 |
| or in more conventional matrix notation | |
| HwH⊗b = Hw⊗y | 4 |
where H is the matrix Bᵢ(xj)), Hw is the matrix Bᵢ(xj))Kjk and HwH = Hw⊗H* (* is transpose and ⊗ is matrix multiplication). So Eq (4) is a conventional regression equation for the fitting coefficients b. The final step in calculating the integral as
A = bᵢaᵢ
where aᵢ are the integrals of the functions Bᵢ(x), or
| A=a*⊗(HwH⁻¹)⊗Hw⊗y | 5 |
The potentially big operations here are the multiplication of the data values y by the sparse matrix Hw, and then by the inverse of HwH. However, there are some simplifications. The matrix K is the identity or a diagonal matrix. For the grid method and mesh method (the early staple methods of TempLS), HwH turns out to be a diagonal matrix, so inversion is trivial. Otherwise it is positive definite, so a conjugate gradient iterative method can be used, which is in effect the direct minimisation of the quadratic in Eq (2). That requires only a series of multiplication s of vectors by HwH, so this product need not be calculated, but left as its factors.
I'll now look at the specific methods and how they appear in this framework.
Grid method
The sphere is divided into cells, perhaps by lat/lon, or as I prefer, using a more regular grid based on platonic solids. The basis functions Bᵢ are equal to 1 on the ith element, 0 elsewhere. K is the identity, and can be dropped.The matrix H has a row for each cell and a column for each data point. It is zero except for a 1 where data point j is in cell i. The product HwH is just a diagonal matrix with a row for each cell, and the diagonal entry is the total number of data points in the cell (which may be 0). So that reduces to saying that the coefficient b for each cell is just the average of data in the cell. It is indeterminate if no data, but if such cells are omitted, the value would be unchanged if the cells were assigned the value of the average of the others.
Multiplying H by vector y is a sparse operation, which may need some care to perform efficiently.
Mesh method
Here the irregular mesh ensures there is one basis function per data point, central value 1. Again K is the identity, and so is H (and HwH). The net result is just that the integral is just the scalar product of the data values y with the basis function integrals, which area just 1/3 of the area of the triangles on which they sit.More advanced methods with sparse matrix inversion
For more advanced methods, the matrix HwH is symmetric positive definite, but not trivial. It is, however, usually well-conditioned, so the conjugate gradient iterative method converges well, using the diagonal as a preconditioner. To multiply by HwH, you can successively multiply by H*, then by diagonal K, then by H, since these matrix vector operations, even iterated, are likely to be more efficient than a matrix-matrix multiplication.Spherical Harmonics basis functions
My first method of this kind used Spherical Harmonic (SH)functions as bases. These are a 2D sphere equivalent of trig functions, and are orthogonal with exact integration. They have the advantage of not needing a grid or mesh, but the disadvantage that they all interact, so do not yield sparse matrices. Initially I followed the scheme of Eq (5) with K the identity, and H the values of the SH at the data points. HwH would be diagonal if the products of the SH's where truly orthogonal, but with summation over irregular points that is not so. The matrix HwH becomes more ill-conditioned as higher frequency SH's are included. However the condition is improved if a kernel K is used which makes the products in HwH better approximations of the corresponding integral products. A kernel from the simple grid method works quite well. Because of this effect, I converted the SH method from a stand alone method to an enhancement of other methods, which provide the kernel K. This process is described here.For a long time I used SH fits, calculating the b coefficients as above, for graphic shade plots of the continuum field. But some other advanced methods provide their own fitted functions.
Grid Infill and the Laplacian
As mentioned above, the weakness of grid methods is the existence of cells with no data. Simple omission is equivalent to assigning those cells the average of the cells with data. As Cowtan and Way noted with HADCRUT's use of that method, it has a bias when the empty cell regions are behaving differently to that average; specifically, when the Arctic is warming faster than average. Better estimates of such cells are needed, and this should be obtained from nearby cells. Some people are absolutist about such infilling, saying that if a cell has no data, that is the end of it. But the whole principle of global averaging is that region values are estimated from a finite number of known values. That happens within grid cells, and the same principle obtains outside. The locally based estimate is the best estimate, even if it isn't very good. There is no reason for using anything else.I described here a rather ad hoc method for iteratively estimating empty cells from neighbors with data, which worked quote well. But the matrix formulation above gives a more scientific way of doing this. You can write a matrix which expresses a requirement that each cell should have the average values of its neighbors. For example, a rectangular grid might have, for each cell, the requirement that 4 times its value - the values of the four neighbors is zero. You can make a (sparse symmetric) matrix L out of these relations, which will have the same dimension as HwH. It has a rank deficiency of 1, since any constant will satisfy it.
Now the grid method gave an HwH which was diagonal, with rows of zeroes corresponding to empty cells, preventing inversion. If you form HwH + εL, that fixes the singularity, and on solving does enforce that the empty cells have the value of the average of the neighbors, even if they are also empty. In effect, it fills with Laplace equation using known cell averages as boundaries. You can use a more exact implementation of the Laplacian than the simple average, but it won't make much difference.
There is a little more to it. I said L would be sparse symmetric, but that involves adding mirror numbers into rows where the cell averages are known. This will have the effect of smoothing, depending on how large ε is. You can make ε very small, but then that leaves the combination ill-conditioned, which slows the iterative solution process. For the purposes of integration, it doesn't hurt to allow a degree of smoothing. But you can counter it by going back and overwriting known cells with the original values.
I said above that, because HwH inversion is done by conjugate gradients, you don't need to actually create the matrix; you can just multiply vectors by the factors as needed. But because HwH is diagonal, you don't need a matrix-matrix multiplication to create HwH + εL, so it may as well be used directly.
I have gone into this in some detail because it has application beyond enhancing the grid method. But it works well in that capacity. My most recent comparisons are here.
FEM/LOESS method
This is the most sophisticated version of the method so far, described in some detail here. The basis functions are now those of finite elements on a triangular (icosahedron-based) mesh. They can be of higher polynomial order. The matrix H can be created by an element assembly process. The kernel K can be the identity.The question of empty cells is replaced by a more complicated issue of whether each element has enough data to uniquely specify a polynomial of the nominated order. However, that does not have to be resolved, because the same remedy of adding a fraction of a Laplacian works in the same way of regularising with the Laplace smooth. It is no longer easy to just overwrite with known values to avoid smoothing where you might not have wanted it, but where you can identify coefficients added to the matrix which are not wanted, you can add the product of those with the latest version of the solution to the right hand side and iterate, removing spurious smoothing with rapid convergence. But I have found that there is usually a range of ε which gives acceptably small smoothing with adequate improvement in conditioning.
LOESS method
This is the new method I described in April. It does not fit well into this framework. It uses an icosahedral mesh; the node points are each interpolated by local regression fitting of a plane using the 20 closest points with an exponentially decaying weight function. Those values are then used to create an approximating surface using the linear basis functions of the mesh. So the approximating surface is not itself fitted by least squares. The method is computationally intensive but gives good results.Modes of use of the method - integrals, surfaces and weights.
I use the basic algebra of Eq 4 in three ways:| HwH⊗b = Hw⊗y | 4 |
| A = b•a | 4a |
- The straightforward way is to take a set of y values, calculate b and then A, the integral which, when divided by the sphere area, gives the average.
- Stopping at the derivation of b then gives the function s(x) (Eq 1) which can be used for graphics.
- There is the use made in TempLS, which iterates values of y to get anomalies that can be averaged. This required operating the multiplication sequence in reverse:
A = ((a•HwH⁻¹)⊗Hw)•y 6
By evaluating the multiplier of y, a set of weights is generated, which can be re-used in the iteration. Again the inversion of HwH on a is done by the conjugate gradient method.
Summary
Global temperature averaging methods, from simple to advanced, can mostly be expressed as a regression fitting of a surface (basis functions), which is then integrated. My basic methods, grid and mesh, reduce to one that does not require matrix inversion. Spherical harmonics give dense matrices and require matrix solution. Grid infill and FEM/LOESS yield sparse equations, for which conjugate gradient solution works well. The LOESS method does not fit this scheme.Appendix - code and libraries
I described the code and structure of TempLS V4 here. It uses a set of library functions which are best embedded as a package; I have described that here. It has all been somewhat extended and updated, so I'll call it now TempLS V4.1. I have put the new files on a zip here. It also includes a zipreadme.txt file, which says:This zip contains:
LS_wt.r master file for TempLS V4.1
LS_fns.r library file for TempLS V4.1
Latest_all.rda a set of general library functions used in the code
All.rda same as a package that you can attach
Latest_all.html Documentation for library
templs.html Documentation for TempLS V4.1
The main functions used to implement the above mathematics are in Latest_all
spmul() for sparse matrix/vector multiplication and
pcg() for preconditioned conjugate gradient iteration
Thursday, November 7, 2019
October global surface TempLS up 0.096°C from September.
The TempLS mesh anomaly (1961-90 base) was 0.87deg;C in October vs 0.774°C in September. This exceeds the 0.056°C rise in the NCEP/NCAR reanalysis base index. This makes it the second warmest October in the record, just behind the El Niño 2015.
The most noticeable feature was the cold spot in NW US/SW Canada. However, the rest of N America was fairly warm. There was warmth throughout Europe (except Scandinavia), N Africa, Middle East, Siberia and Australia. Sea temperature rose a little.
Here is the temperature map, using the LOESS-based map of anomalies.
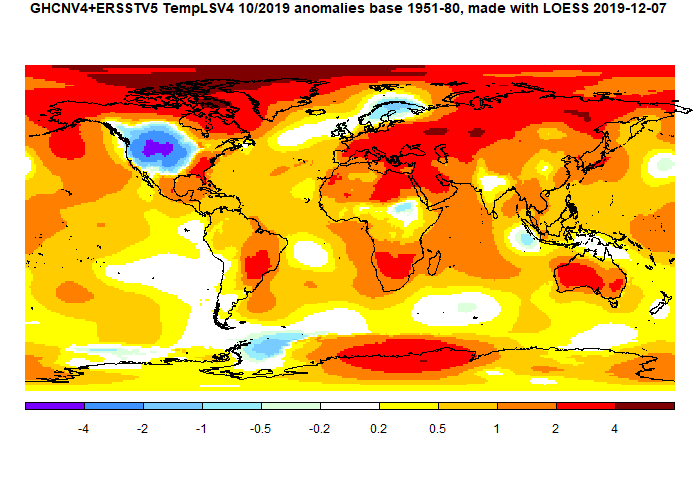
As always, the 3D globe map gives better detail.
The most noticeable feature was the cold spot in NW US/SW Canada. However, the rest of N America was fairly warm. There was warmth throughout Europe (except Scandinavia), N Africa, Middle East, Siberia and Australia. Sea temperature rose a little.
Here is the temperature map, using the LOESS-based map of anomalies.
As always, the 3D globe map gives better detail.
Sunday, November 3, 2019
October NCEP/NCAR global surface anomaly up 0.056°C from September
The Moyhu NCEP/NCAR index rose from 0.419°C in September to 0.475°C in October, on a 1994-2013 anomaly base. It continued the slow warming trend which has prevailed since June. It is the warmest October since 2015 in this record.
There was a big cold spot in the US W of Mississippi, and SW Canada. WWarm in much of the Arctic, including N Canada. Warm in most of EWurope, but cold in Scandinavia. Cool in SE Pacific, extending into S America.
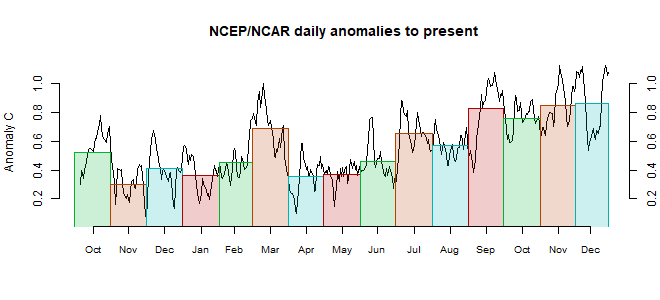
There was a big cold spot in the US W of Mississippi, and SW Canada. WWarm in much of the Arctic, including N Canada. Warm in most of EWurope, but cold in Scandinavia. Cool in SE Pacific, extending into S America.
Subscribe to:
Posts (Atom)











