There has been discussion recently of the confidence intervals of the Holocene temperature reconstruction of Marcott et al. I've been posting a lot on this paper recently, here, here, here, and here. So have others, and I got involved in a discussion at Climate Audit. There they noted a dip in Marcott's confidence intervals at about the period of his anomaly base (4500-5500 BP). BP means before present, taken to be 1950. The discussion went on to Lucia's where I believe there is a post on the way.
So I want here to review first what reconstructions are trying to do, why anomalies are needed, why they are often done with subsets of the available time as base, and why this inevitably causes a "dimple" in the CI's.
Reconstructions.
So we have a set of estimated temperatures over various time periods in the past. Marcott's are typical. Usually in a multi-proxy recon, they are of diverse types and come from a mixture of places that are hot, cold and in between.There has been much discussion of tree-ring and other proxies that require calibration to instrumental observations. Marcott's don't, and I'm going to skip this complication.
In fact, the formation of a global instrumental temperature index has essentially the same issues, and is more familiar and better established.
So we have a bunch of time sequences and want to express the variation that they have in common.
Naive Reconstruction.
So why not just average? Well, partly there's the question of, what does it mean to average, with Marcott, a whole lot of ice core and marine/lake environments. Does that give a world average?Most organisations that provide surface temperature indices don't do this. GISS explains why, also NOAA.
About the only exception that I am aware of is that for historic reasons (I think) the NOAA produces average US figures. This is typical of the problems it can cause. There are actually two networks, USHCN and CRN. They produce two different average temperatures. The linked post argues that the new network, CRN, is better and shows cooler temps than USHCN did many years ago, so the US must be getting cooler. But it turns out that CRN is on average higher, so the temperatures are bound to be cooler. Which is right? You can argue for ever about that.
Here's another indicator of the silliness that can result. The claim is that to make the globe temp look warmer, the NOAA through GHCN had been selectively eliminating cool climate stations.
Now in fact cool regions of NH particularly had been over-represented. That doesn't matter too much; gridding takes care of it, mostly. But it matters even less because anomalies are used - ie temperatures with ref to some average. So even without gridding a shift in station climates has little effect.
That's the key reason for a move to anomalies - absolute temperature averages depend absolutely on the stations in the mix, and if stations go missing for whatever reason, the average shifts.
Anomaly reconstructions
One good thing about anomalies is that they vary smoothly over space. You can see that by leafing through the maps here. That makes it possible to sum in a way that approximates a spatial integral. A spatially averaged anomaly reconstructions should be made up of a weighted average which best emulates an integral.But the key benefit of using anomalies is that they minimise the effect of missing data. All stations in the sum have expected anomaly value close to zero. If an anomaly is missing, its effect on the average is as if it had the same value as that average, which is not likely o be far wrong.
The "dimple" which I will discuss is not likely to be visible if the anomaly is taken with respect to the average of the data for each proxy. But there is a good reason to use a common base period, as all the major surface indices do. Using different periods for different proxies can affect the trend.
Here's an example. Suppose just two stations, A and B. both with just a linear temp history. A has a record from 1900 to 1975, and rises from -1°C to 0.5°C. B goes from -0.5°C in 1825 to 1°C in 2000. As you'll see they have the same temps from 1926 to 1975, and a trend of 2°C/Century, and are both 0 in 1950.
If you use 1925-1975 as the anomaly base period, 0 is added to each, and the recon is just the line from -1 in 1900 to 1 in 2000, a slope of 2 as expected.
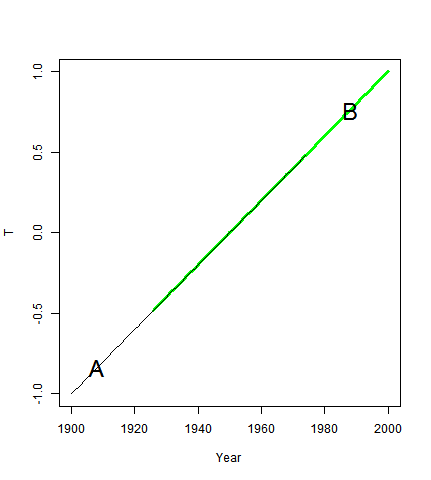
But if you use the whole period, averaging where data exists, then 0.25 is added to A, which then goes from -0.75 in 1900 to 0.75 in 1975. And 0.25 is subtracted from Bm, which goes from -0.75 in 1925 to 0.75 in 2000. The trend is now 1.333 °C/Cen.
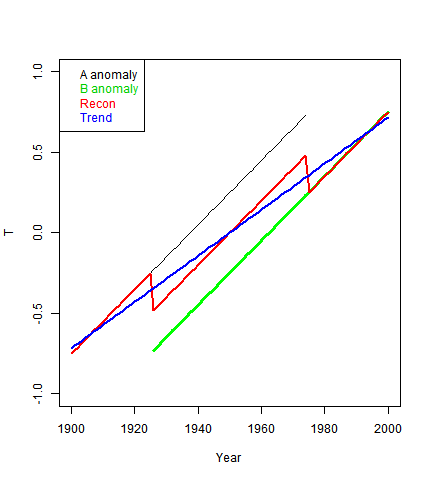
The simplest solution is to find a range where all proxies have data to use as a base. This is what Marcott et al did, using 4500-5500 BP. For surface stations, more elaborate algorithms are required, which generally take advantage of the greater density of stations.
Confidence intervals
The reconstruction is a mean across proxies, and the natural measure of uncertainty is the pointwise standard error of that mean. That is what was used in, say, Loehle and McCulloch (see p 95). And it seems to be the main part of the Marcott calculation, which also incorporates Monte Carlo variation for date and calibration uncertainty. I say seems, because their description is noy entirely clear, and the linked CA post seems to interpret as not including variability of the mean. But that would be a strange thing to do when they calculate that mean.Marcott et al show 1σ levels, so I will use that convention.
Toy example
I'm going to use a linear algebra description, with indices and summation convention (a repeated index is summed over its range). Suppose we have P identical proxies, each from a distribution with an expected value zero and random part &deltapt. p is an index over proxies, t over time (N steps). The toy naive recon isTt=wpδpt
where the w's are the weights. I'll assume they are all 1/P, but the term is kept here to carry the suffix to show summation. However I'll now shift to saying that the δs are from the same distribution over p, so the upshot is that the CI for T is sd(δ).
Now in this case we have so many suppositions that there's no reason to take anomalies, but I want to show the effect of doing so. And I want to present it in linear algebra form, Taking as anomaly over a block of M time steps is equivalent to multiplying by a NxN matrix D, made by subtracting from the identity a matrix with M columns comtaining 1/M, zero elsewhere.
Then if the covariance matrix of δ is K, the covariance matrix of the anomalised sequence will be DKD* (* is transpose). The CI's will be the square roots of the diagonals of that matrix.
If the δs had been unit white noise, K would be the identity, and it is left to the reader to verify that the diagonals of DKD* are 1+1/M outside the block of M (anomaly base) and 1-1/M within. I've shown that in two alternative ways here and here (note correction here, which suffered thread drift). That's the dip.
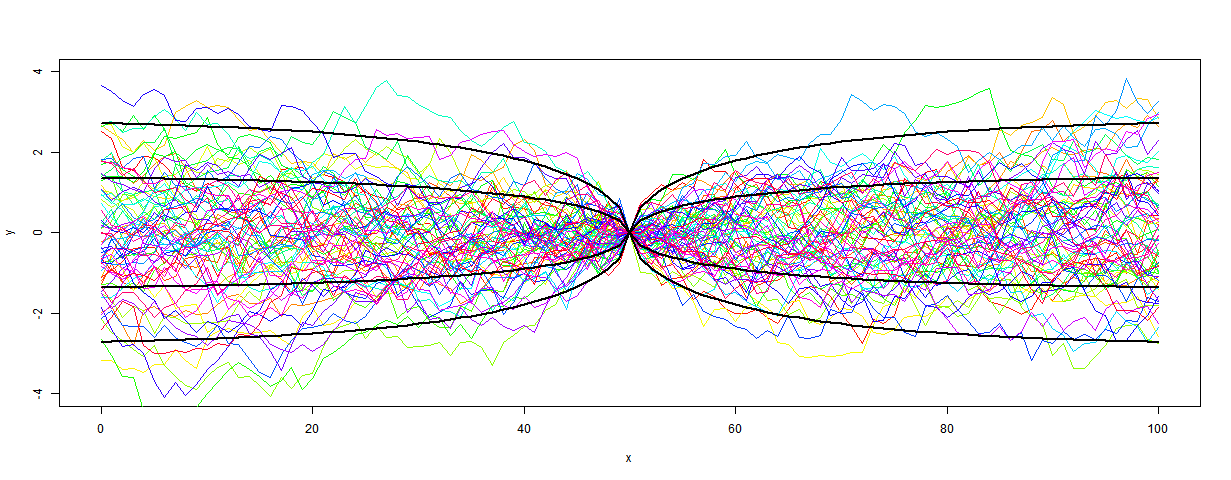
More interesting is the case with AR(1) noise, parameter r. Then the matrix Kij = r^|i-j|. I'll work out the general for,\m in the morning, but I want for the moment to show the interesting particular case when M=1. This has caused a lot of discussion, because the uncertainty goes to zero. Some people cannot believe that, but it is a simple consequence of the fact that the anomaly definition guarantees that you will have a zero there.
In the case of white noise, that can seem like a semantic argument, but with AR(1) it's real. Layman Lurker at Lucia's calculated the case r=0.95. I want to show the theoretical CI's, to show how they tend to zero - this is real arithmetic, not just arguing about definitions.
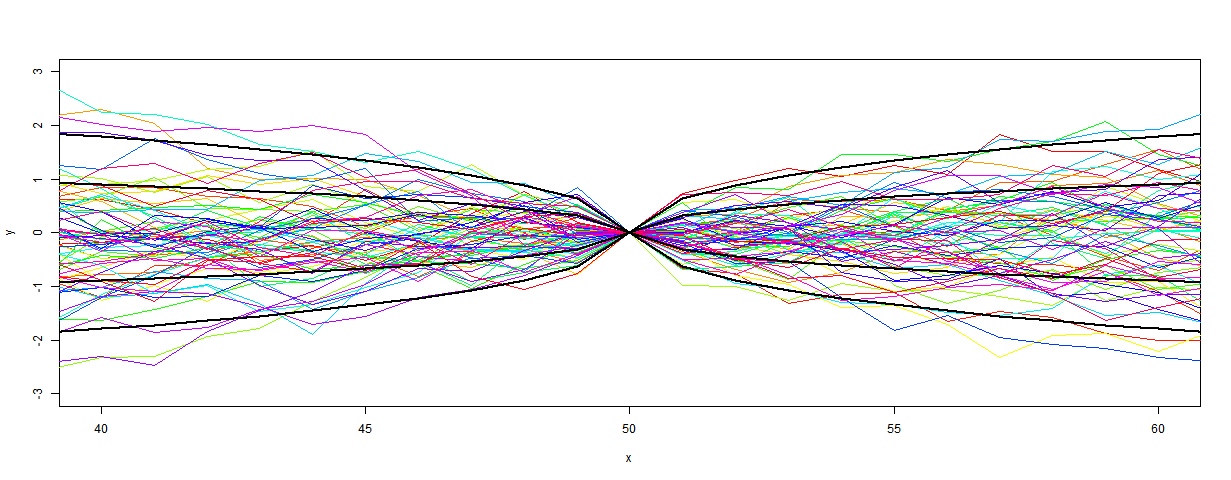
When you work out the DKD* product now, the diagonal is just 2*(1-r^|i-i0|), where i0 is the anomaly base point. And again, the CI's are the sqrt. Here it is plotted with both 1σ and 2σ CI's. I've taken P=70, as Layman Lurker did - you might like to compare with his plot.
Here's a closeup of the anomaly base region
To be continued.












"For surface stations, more elaborate algorithms are required, which generally take advantage of the greater density of stations."
ReplyDeleteAbsolutely. Unfortunately more elaborate algorithms are not always used. I just did a calculation with HadCRUT4 in which I rebaselined the MAP series on 1991-2010 instead of 1961-1990. The trend on 1997-2013 increases by 0.02C/decade (despite a reduction in coverage).
The reason? Because cells are dropping out during the trend period, and those cells are warm relative to the baseline period. As you note, baselining on a period close to or overlapping the trend period minimises the effect of changes in coverage during the trend period.
Kevin C
Kevin
ReplyDeleteInteresting. I think that reflects that fact that they use elaborate algorithms to overcome station dropout and anomaly base, but take less care with cell dropout, which is a rather different problem. Yes' I think there should be much more effort to in effect anomalise cells.
Actually HadCRUT4 just uses the basic common anomaly method, so the station and cell baselines are identical. i.e. because all stations in a cell have zero mean on 61-90, the cell itself also has zero mean on 61-90.
ReplyDeleteSo HadCRUT4 has 2 problems over and above the general problem of coverage bias:
1. Baselining on a period distant from the period of interest means that cell dropout causes bias.
2. Baselining on a period distant from the period of interest means increasing station dropout because stations require a homogenous spanning both the baseline period and the period of interest.
(2) could be fixed by adopting a more modern homogenisation method like yours, which in turn would help to mitigate (1), particularly if the baseline period is then shifted towards the present.
Kevin C
Very interesting post Nick. Thanks. Kevin C raises some good points with respect to station drop out and is something I have thought about with proxy drop out as well. The situation with proxies would be made more serious due to the highly autocorrelated errors relative to the thermometer record. I see that Steve M has alluded to this conceptually as well in his TN05-17 post.
ReplyDeletethe upshot is that the CI for T is sd(δ).
ReplyDeleteThe problem here is that people it appears some people are claiming the CI for T where T is the reconstruction itself is the measurement uncertainty for the proxy reconstruction. But it's not. This argument has nothing to do with anomalies.
Is this Lucia speaking? I think that the anomaly averages are as close as we can get to reconstructed temperature, and that the CI's have to be determined, primarily, by reference to the observed variability of the anomaly data. I'm actually unclear on what is meant by measurement uncertainty here. There are things like the fuzziness of the calibration and dating which Marcott et el handle with Monte Carlo. But the primary issue is the observed scatter of the underlying proxy data.
DeleteBut as to what people claim, well, I'd need to see quotes. Marcott et al were clear that they were showing an anom aly plot, and so it's reasonable to expect that the CIs drawn on it are the CIs of that anomaly.
Nick: Yes. It's Lucia.
ReplyDeleteI'm actually unclear on what is meant by measurement uncertainty here.
If you know you are unclear on this, why don't you learn what people mean by measurement uncertainty here?
With respsect to this
But the primary issue is the observed scatter of the underlying proxy data.
That's not the primary issue driving any arguments I'm reading. The primary issue is that measurement uncertainty should be based on the standard deviation of (T_reconstruction- T_true) where T_true is the temperature that actually happened.
You seem to be worrying about the difference in the variance of T_reconstruction v that of (T_reconstruction_rebaselined) Neither of these is the standard deviation of (T_reconstruction- T_true) which would represent the error.
You can't resolve this issue by discussing the difference between statistics of (T_reconstruction_rebaselined) v, T_reconstruction because that has little to do with the question. Yes. Those look different. But the question is about the definition of measurement uncertainty. I'm going to email you a question for clarity.
Nick, we basically found the same thing in our review of Hansen. Zeke had a bunch of these cool "wasp waist" plots. I don't think they made it into his final memo.. hmm maybe I can talk him into chiming in
ReplyDelete