Why is June hotter seen with GHCN V4 than V3 - and lots of active graphics.
This post is a follow-up to one
a few days ago on differences seen calculating monthly global averages using
TempLS and
version 4 of GHCNrather than V3. It followed a
post of Clive Best, who has a similar program, and was finding differences. I too found that June 2019 rose about 0.07°C while using GHCN V3 did not show a rise. I think overall differences are small, but I wanted to look at the underlying arithmetic.
So, as
foreshadowed, I adapted my program to use its
LOESS based calculation and
graphics, in which I could calculate differences. But there was mission creep, as I found that being able to put disparate data on the same equally spaced grid made a lot of other things possible. So I showed also the effects of homogenisation. It does answer the question of why V4 made a difference this month, but there is a lot more to learn.
First let me tell the many uses of the main graphic, which is shown below. It is the familiar
WebGL trackball Earth. You can drag it about and zoom. Click on the little map to quickly center at a chosen point. But importantly for this inquiry, you can control the content. The checkboxes top right let you switch on/off the display of V3 and V4 or SST nodes, or the shading (called "loess"), or even the map. And the radio buttons on the right give the choice of five data sets for June 2019, which are
- Un V4-V3 which is the difference of TempLS anomalies using unadjusted GHCN data from V4 and V3.
- Adj V4-V3 the corresponding difference using adjusted GHCN data (QCF, pairwise homogenised)
- V4 Un - Adj the difference between unadjusted and adjusted data, for a V4 calculation
- V4 Un - Adj same for V3
- V4 Unadjusted just the TempLS anomalies using V4. It is the LOESS version of my regularly updated mesh plot.
So I'll show the plot here, with below an expanded discussion of what can be learnt from it.
Improved coverage in GHCN V4
This is shown most clearly if you switch off loess, and toggle the boxes controlling V3 and V4. The improvement of coverage is greater than I had thought, and as I will show is the basis for V3/V4 discrepancies.
The V3/V4 difference for June, and reasons.
One thing that surprised me was the coherence of the difference plots. The LOESS does some smoothing - you can estimate the effect by looking at the smudging around coastlines. The SST is the same between versions, so color in the sea means either islands or smoothed land. It fades basically exponentially, so color difference tends to exaggerate the spread. It's surprising because you would expect that station differences between V3 and v3 would be fairly random.
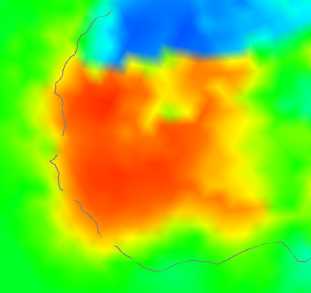
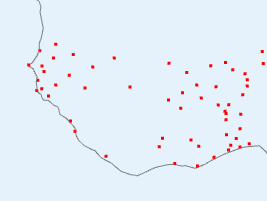
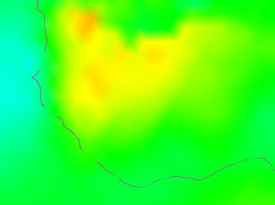
But only if both types are represented, and that is the key here. There is, for example, in Un V4-V3 a big warm patch around Senegal. I'll show also the station distribution and the anomalies:
 |  |  |
| V4-V3 difference | V4 stations | V4 anomaly |
I haven't shown the V3 stations, because basically there aren't any (check the figure). So how did V3 cope? It used information from nearby, a lot of which was sea. V4 had much better coverage, so the region is predominantly represented by land. And as the third column choes, the land was warmer, by anomaly. Not a lot, but watch for the different color scales here. The apparent warmth in the first column is a much smaller temperature difference - the scales are about 4:1.
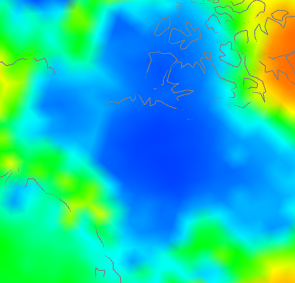
So here is where a discrepancy arises - an area which V4 covers much better, which happened to be warm that month. Here is an example going the other way in NW Canada:
 | 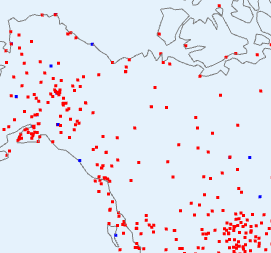 | 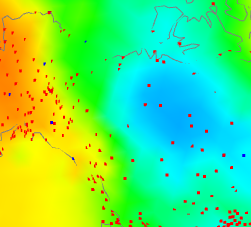 |
| V4-V3 difference | V3 and V4 stations | V4 anomaly |
have shown the same tableau, but this time the centre plot shows V3 stations as well (in blue) since there are a few. But not many. Again what is happening is that the rather faint blue patch on the right, because it is picked up by V4 but hardly by V3, turns into a V4-V3 discrepancy on the left. One more case - Antarctica:
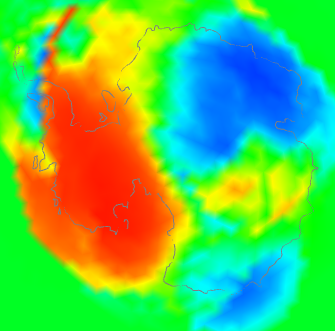 | 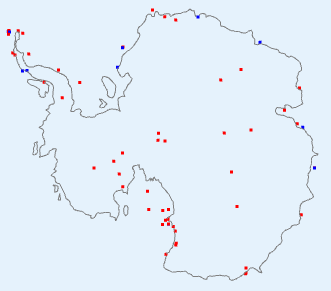 | 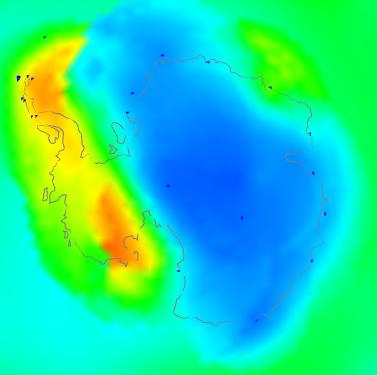 |
| V4-V3 difference | V3 and V4 stations | V4 anomaly |
This is a bit of both. It shows a discrepancy plot warm (ie high V4-V3) in the W, opposite in the East. The station plot shows a big increase in coverage in the interior, and also on the peninsula. And the right shows that the actual anomaly was also strongly divided between W and E. You might ask - why did the strong warmth in the East show a relatively small discrepancy? I think it is because although the V3 stations were sparser, they did give reasonable coverage around the coast of EA. So although the interior had to look far afield to infer temperatures, mostly it found land rather than sea.
So overall I think that is the cause. There are a few regions around the Earth where V4 has much better coverage. If these happen to align with anomaly patterns, those patterns will be reflected in the V4-V3 difference, and because there are only a few, from time to time they will align by chance.
I think this also explains the small persistent long term changes. As warming proceeds overall, it will more often happen that the anomaly patterns in V3-sparse areas with vary from SST on the warm side, producing a warm V4-V3 difference, which will accumulate.
What about adjusted data, whch seems to show a little more warming? I think it just fixes some aberrant cases which would reduce the effect in unadjusted data. Here is another tableau from Antarctica
| 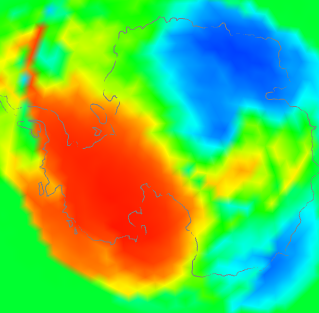 | |
| Unadjusted V4-V3 | Adjusted V4-V3 | |
The unadjusted had a number of blue spots along the Antarctic peninsula. Homogenisation identified some of these as biases that could be corrected. Whether right or wrong, the arithmetic result is of a discrepancy that integrates to a higher value, because of reduced noise.
To summarise, I think the reason is not that V3 stations were reporting temperatures different to V4; it is that in some regions they weren't reporting temperatures at all, and the discrepancies are a resulting artefact. So where it happens (not much), V4 is better than V3. This may not affect methods like HADCRUT and NOAA in the same way, since they more rigidly separate land and sea. But I think Clive's method will respond in the same way as mine.
Coverage patterns
Again, to see this I'd recommend switching off loess, and then between V4nodes on and V3nodes on. I was actually surprised at how many areas in June were much better covered by V4. Large areas of Africa like the Senegal area above, are much better. There are, of course, still gaps. Antarctica is much better in the interior. Australia is better, and so is the Amazon region.
Adjustment patterns
I'm looking now at radio buttons 3 (V4 Adj - Un) and 4. If you look at the color keys, the adjustments are quite small. I was a bit surprised that there are any at all. So it probably isn't that useful to talk much about June, since it is in older times that adjustment has more effect. Still, June is what we have here - I may try and look at more data in a later post.
Again the patterns are mostly quite triking. The US is an exception, where there may be a residual effect of TOBS adjustment. Africa is an interesting case, where two large regions are warmed, and one is cooled. The Amazon is cooled, but further south is warmed. China and Thailand are warmed.
Button 4 (V3 Adj - Un) shows the corresponding pattern with V3. This time North America is mostly warmed. The Arctic ocean (from land stations) is cooled. Africa is more cooled than warmed. N China and west are warmed, but not the south. W Antarctica is cooled.
I don't want to go too much further into this, as I don't think the most recent month is the best place to look for adjustment effect. I'll hope to do more.
More plot details.
Usually I show the actual mesh being used for shading. That isn't so important here, but if you want to see it, and read more about the icosahedral mesh which underlies the Loess method, it is described
here.
Being V3 (I will write up) of the WebGL facility, there is improved zooming, with buttons as well as right button motion.
The Match button enforces the same color scaling, but I don't think that is wise here. I haven't included station names, so clicking won't bring them up. The data file is already over 1 Mb, and it would be messy with the two station sets.











