I have now posted three simplified emulations of the Marcott et al reconstruction, here, here, and here. Each used what I believed to be their assumptions, and I got comparable means and CI's. And I think the Marcott assumptions are fairly orthodox in the field.
But I've been wondering about the noise structure, and in particularly the effect of the extensive interpolation used. The proxies typically have century+ resolution, and are interpolated to twenty year intervals.
The interpolated points are treated as independent random variables. They have about the same uncertainty (amplitude) as data points. But they are certainly not independent.
I find it useful to think about interpolation in association with the triangular basis (shape) functions of the finite element method. I'll talk about those, and about the kind of linear model approach to reconstruction that I described in my last post. Below the jump.
Basis (shape) functions
These are described here. For this context, they are the simplest possible - triangles of unit height. From Wiki, here's a linearly interpolated function: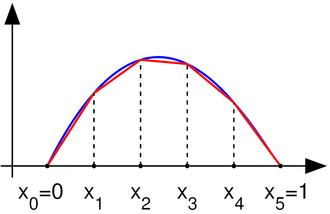
That has regularly spaced intervals, but that's not at all essential. The corresponding basis functions are shown here:

Wiki doesn't show this well in the diagram, but the interpolate is achieved just by multiplying each basis function by the corresponding data point and adding the results, as shown here:
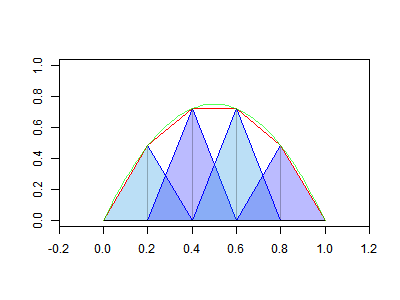
A major elegance of the finite element method is that you can then switch attention to the elements (intervals) and assemble the result (interpolate) by operating on the fractions of the basis functions that lie with ine element.
Linear model
In the last two posts (here and here.) I have described how the collection of proxy data (Ttp) can be fitted to a simple linear model:Ttp=Tt+Pp + error
where Tt is the global temperature function being sought and Pp are offsets associated with each proxy (index p). When I did that, the data points were interpolated to 20-year intervals, and that was the spacing of t. So there were 565 Tt parameters over 11300 years.
With 20-year basis functions Bt (τ) you can interpret Tt as a continuous function of time τ:
T(τ)=Σ Tt Bt (τ)
That's the linear interpolate; the Tt are still the parameters we're looking for by fitting.
In principle, I believe you should enter just one equation for each data point, which gives a reasonable chance that the residuals are independent. But how to make that equation?
Collocation
I'll now write s instead of t when thinking about the irregularly spaced data timesYou could say just that a data point Tsp stands on its own, and the equation associated with it is:
Tsp=T(s)+Pp + error
T(s) would be expressed as Σ Tt B_t(s)
That looks like potentially a large sum. However, only two at most basis functions overlap s, so only two of the T coefficients are implicitly involved.
However, that would give low weighting in the equation system to proxies that had sparse data values. They may not deserve that, because the data value may be representative of a longer interval. In many cases, sparse proxies are so because it was decided that there just wasn't much point in expressing numbers at finer resolution; they just don't change enough.
Galerkin
The extreme alternative view is to say that the data point is representative of the interval up to the next point. That's really what is assumed when the data is linearly interpolated. In our terms the data point represents a contribution measured by its product with its basis function.Well, that's OK, but we need numbers. In the Galerkin method, that is obtained by multiplying the continuum proxy equation
Tps Bs(τ)=T(τ)+Pp
by that same basis function Bs(τ) and integrating. The integration is in principle over all time, but the basis function is only non-zero on the intervals adjacent to s.












"In many cases, sparse proxies are so because it was decided that there just wasn't much point in expressing numbers at finer resolution; they just don't change enough."
ReplyDeleteThat may be a dangerous assumption. One of the examples I wanted you to look at was the Tierney et al, TEX86 reconstruction. The high resolution extension is all over the place. Compaction just smears or smooths the points into a natural average in the longer term reconstructions.
Well, it's an observation (or speculation, if you prefer) rather than an assumption.
DeleteI looked at the Tierney data; that which they used seems regular enough, with a sharp peak about 6500, and ragged after 11000BP. But I guess you're referring to another higher res version. Of course that's another side of apparent low res - it may be that the data was locally averaged before publication.
Nick, How they are averaged should be considered I would think. There was a big to do over Keigwin's Sargasso Sea Reconstruction and his averaging method versus the uncertainty added in trying to get higher resolution. I would think that you would have to include full proxy uncertainty range unless they are all standardized.
DeleteBTW, there seems to be another issue with the Tierney Lake Tanganyika proxy. The scale of the two peaks appears to be off by a degree or so. The ~11000 ka BP appears to be amplified and the ~5400ka BP peak subdued by the anomaly method, binning or both. I would think that is a pretty fatal flaw.
DeleteDallas,
ReplyDeleteI'll look at that. I'm currently trying to see how the date uncertainty smoothing works. That may help us here.