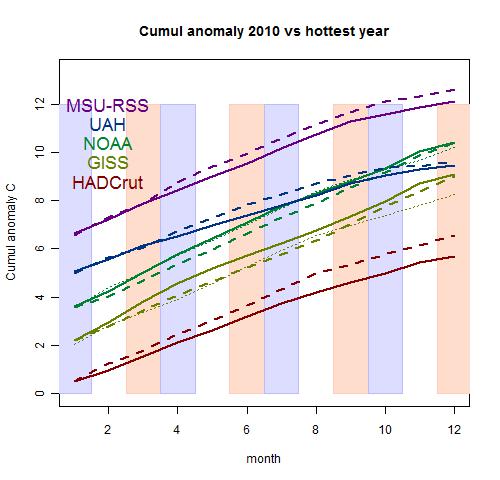
The Math basis of TempLS Ver 2
For Version 1 of TempLS I posted a PDF guide, TempLS.pdf, to the mathematical basis. It's a useful starting point here.But this time I'm going to try to do it in HTML below. Colors help.
For more Version 2 information:
Notation
I need to use a summation convention. I'm referring to various matrices etc as just indexed sets, and when they are multiplied together, every index that appears twice is understood to be summed over the range of that index. It's called a dummy index, because it doesn't matter what symbol you use (as long as it's not used for something else). Once the summation is done, that index doesn't connect with anything else.I'll be talking about weighted least squares, and an exception is needed for the weight function. It's indices are sometimes put in brackets, which means they should not be counted in this pairing. The index still varies with any summation that is going on.
The reason for this is that summation signs are difficult in HTML. But also it gets easier with colors. I'll color indices subject to summation blue, standalone indices red, and exception indices lime green.
So multiplying two matrices A and B (C=A*B) would be represented:
Cik = Aij Bjk
The model
We have, on the GHCN and similar sets, a number of stations (s), with temperature readings (x) by year (y) and month (m). m varies 1:12. The model is that x can be represented by a local temperature L, with a value for each station and month (seasonal average), and a global temperature G depending on year alone.xsmy ~ Lsm + Gy
It's useful to maintain a convention that every term has to include every red index. So I'll introduce an identity Iy, for which every component is 1, and rewrite the model as
xsmy ~ IyLsm + IsmGy
Weighted least squares.
The L and G are parameters to be fitted. We minimise a weighted squares expression for the residuals. The weight function w has two important roles.- It is zero for missing values
- It needs to ensure that stations make "fair" contributions to the sum, so that regions with many stations aren't over-represented. This means that the sum with weights should be like a numerical integral over the surface. w should be inversely proportional to station density.
Differentiation
This is done by differentiating this expression wrt each parameter component. In the summation convention, when you differentiate wrt a paired index, it disappears. The remaining index goes from blue to red. The original scalar SS becomes a system of equations, as the red indices indicate:| Minimise: | w(smy)(xsmy - IyLsm - IsmGy)2 |
| Differentiate wrt L: | w(smy)Iy(xsmy - IyLsm - IsmGy) = 0 |
| Differentiate wrt G: | w(smy)Ism(xsmy - IyLsm - IsmGy) = 0 |
The identity operations have been useful, but can now be rationalised. The equations become:
| Differentiate wrt L: | w(sm)y IyLsm + wsmy Gy = w(sm)y xsmy |
| Differentiate wrt G: | wsmy Lsm + wsm(y) IsmGy = wsm(y) xsmy |
Equations to be solved
These are the equations to be solved for L and G. It can be seen as a block system:A*L + B*G = X1
BT*L + C*G = X2
combining s and m as one index, and where T signifies transpose. Examining the various terms, one sees that A and C are diagonal matrices, so the overall system is symmetric.
The first equation can be used to eliminate L, so
(C - BTA-1B)*G = X2 - BTA-1X1
This is not a large system to solve - G has of order 100 components (years). But the multiplications to create it are time-consuming. The alternative offered by TempLS is to use the conjugate gradient method on the whole system. This turns out to be fast and reliable.
There is a rank deficiency in that a constant could be added to L and subtracted from G. This is resolved by forcing the first component of G to be zero. Later this can be adjusted to set the base period for G as an anomaly. The same issue arises with spatial models below.
Spatial dependence
That is what was done in Ver 1. In version 2, it is called model 1.The weight function w was estimated using a grid to get the station density locally.But we could try to put more parameters into G. In particular, we could try to let it vary spatially, and this is what is new in V2.
We need a set of orthogonal functions, expressed as a matrix Psk, being a value at each station, where k indexes the functions. Actually, the functions needn't be strictly orthogonal, but should express the range of possible spatial variation.
The continuous function that this produces is Pk(lat,lon)Hk, where H is a set of coefficients to be found.
Then it's simpler if the dependence of G on years is fixed in advance. A model expressing these dependences is:
xsmy ~ IyLsm + ImJyPskHk
For J, there are two forms used:
- J=y, yr0≤y≤yr1 gives a trend in C/yr between those years. This is model 2
- J=1, yr0≤y≤yr1 gives an average C between those years. In Ver 2.0, this is model 3, and is restricted to a single year.
Differentiation
This time the sum of squares of residuals is differentiated wrt L and H:| Minimise: | w(smy)(xsmy - IyLsm - ImJyPskHk)2 |
| Differentiate wrt L: | w(smy)Iy(xsmy - IyLsm - ImJyPskHk) = 0 |
| Differentiate wrt H: | w(smy) ImJy Psk (xsmy - IyLsm - ImJyPsjHj ) = 0 |
Again it can be re-expressed as a symmetric system:
| Differentiate wrt L: | w(sm)y IyLsm + w(s)my JyPskHk = w(sm)y xsmy |
| Differentiate wrt H: | w(s)my Jy Psk Lsm + w(smy) ImIm JyJy Psk Psj Hj = w(s)m(y) Jy Psk xsmy |
Solving
Solving is by the same elimination method - the multiplier of L in the first equation is again a diagonal matrix. The conjugate gradient method is less attractive here.
Spatial methods can be used over the whole globe or over sub-regions. There is a tension between the resolution you would like to get by using many orthogonal functions, and the information available. If there are too few stations for the resolution, the final matrix will be ill-conditioned, and spurious results will occur.
TempLS deals with this by doing a diagonalization of that final symmetric matrix, and inverts a subsystem based on the larger eigenvalues - a kind of PCA. The user can specify where the cutoff occurs, using a variable eigcut. This should be a small number, between 0 and 1, but closer to 0. I often use 0.01 - higher values are more conservative. A strategy is to try different values until the results do not depend on your choice.
Orthogonal functions
The types currently available are- Type 1 - spherical harmonics, for the whole sphere
- Type 0 - trig functions (of lat-lon) for use on approximately rectangular regions