Some original code and data used in the paper is available at Nychka's site at NCAR. So I downloaded it. It's elegant in R. Just 11 lines of actual calculation to get from the proxy data to a set of proxy eigenvectors, with decentered scaling. And then, of course, R does the regular PCA for comparison in one line.
Then Ron Broberg put up a very helpful post drawing attention to a discussion by Dr Richard Smith of a recent paper by Li, Nychka and Ammann. As Ron says, it's well worth reading (as is Ron's post). I've only just started.
The R code
To get me going, I re-commented Ammann's code, to help my understanding. I'll show it, with the Figures, below the jump.So the next stage is for me to recheck the things that are commonly said about the various proxies, and how they are reweighted. Later it might be possible to adapt the code for the Mann08 (Tiljander etc) analysis.
Here's Ammann's code for the decentred PCA. My comments have a double ##:
# read in data
## scan a big file of proxy data - 70 proxies, 581 years from 1400:1980
## North America
T<-scan("2004GL021750-NOAMER.1400.txt",skip=1)
T<-matrix(T,nrow=581,ncol=72,byrow=TRUE)
tree<-T[1:581,3:72]
## tree is the matrix of proxy data over 1:581 years (1400:1980) - 70 proxies
tt<- c(1400:1980)
# MBH- uncentered PCs GRL Data, Caspar Ammann's code
# =======
## This part rescales tree according to the mean and sd to get xstd
m.tree<-apply(tree[503:581,],2,mean)
s.tree<-apply(tree[503:581,],2,sd)
xstd<-scale(tree,center=m.tree,scale=s.tree)
## regress 1902:1980 columns of xstd against years in calibration period
fm<-lm(xstd[503:581,]~c(1:nrow(xstd[503:581,]))) #fit linear model to calibrati$
## fm($residuals) is the set (79x70) of residuals
## sdprox(1:70) is the sd for each proxy over the 79 years
sdprox<-sd(fm$residuals) #get residuals
## so now the xstd are rescaled relative to the calib period.
## This creates the famous MBH98 decentering (note center=F)
mxstd<-scale(xstd,center=FALSE,scale=sdprox) #standardize by residual stddev
## Now do the svd decomposition on mxstd = u * d * v
w<-svd(mxstd) #SVD
## w$u is the 581x70 matrix of ordered eigenvectors
## w$d are the eivals = 164.3 83.1 58.9 50 45.6 ...
PCs<-w$u[,1:5] #Retain only first 5 PCs for c$
## At this stage, "retain" is just the number of PC's that we calculate
m.pc<-apply(PCs[503:581,],2,mean)
s.pc<-apply(PCs[503:581,],2,sd)
PCs<-scale(PCs,center=m.pc,scale=s.pc)
## Now each PC is rescaled to mean=0, sd=1, again on 1902:1980
## Now just plot - fig1() and fig2() are plot routines which also call princomp().
source("fig1.R") # only need to source these fucntion once if they
source("fig2.R") # are saved in your work space.
## I changed the output from pdf to jpg for html posting
jpeg("fig1.jpg", width=900, height=800)
fig1()
dev.off()
jpeg("fig2.jpg", width=900, height=600)
fig2()
dev.off()
Here's the routine for fig1(). Note the one-line calcs for the regular PCA:
`fig1` <-
function(){
par( mfrow=c(3,1), oma=c(6,0,0,0))
par( mar=c(0,5,2,2))
## This does the whole PCA by the covariance method (cor=F is the default)
## It returns the "scores" - ie the first 5 (here) principal components
PCs.3<- princomp(tree)$scores[,1:5]
## This does the PCA by the correlation method
PCs.2<- princomp( tree, cor=TRUE)$scores[,1:5]
## tt is 1400:1980. PCs[,1] is first PC. The scale() seems redundant
## but isn't, because it was previously scaled to the calib period.
plot( tt, scale(PCs[,1]), type="l", lty=1, xaxt="n", ylab="Scaled PC1")
abline(h=0,col="blue")
title("MBH centering and scaling in instrumental period",adj=0)
plot( tt, -1*scale(PCs.3[,1]), type="l", lty=1,xaxt="n", ylab="Scaled PC1" )
abline(h=0,col="blue")
title("First PC using covariance",adj=0)
plot( tt, scale(PCs.2[,1]),
type="l", lty=1, xaxt="n", ylab="Scaled PC1")
abline( h=0, col="blue")
title("First PC using correlations",adj=0)
par( oma=c(0,0,0,0), mar=c(5,5,2,2))
axis( 1)
mtext( side=1, line=3, text="Years")
}
Here's the resulting plot:

|
`fig2` <-
function(){
par( mfrow=c(2,1), oma=c(5,0,0,0))
par( mar=c(0,5,3,2))
## as for fig1()
PCs.3<- princomp(tree)$scores[,1:5]
PCs.2<- princomp( tree, cor=TRUE)$scores[,1:5]
## Plot the decentred MBH PC1
plot( tt, scale(PCs[,1]),
type="l", lty=1, xaxt="n", ylab="Scaled PC1")
abline( h=0, col="blue")
title("First five covariance PCs projected (green)
onto MBH centered and scaled PC (black)",adj=0)
## Regress the covariance PCs against decentred
lm( scale(PCs[,1]) ~ PCs.3[,1:5] ) -> out
## Plot the resulting fitted curve
lines( tt, predict(out), col="green", lwd=2)
lines( tt, scale(PCs[,1])) ## ?? this just seems to replot the MBH PC1
## Same, but done for the correlation method
plot( tt, scale(PCs[,1]),
type="l", lty=1, xaxt="n", ylab="Scaled PC1")
abline( h=0, col="blue")
title("First five correlation PCs projected (green)
onto MBH centered and scaled PC (black)",adj=0)
lm( scale(PCs[,1]) ~ PCs.2[,1:5] ) -> out
lines( tt, predict(out), col="green", lwd=2)
lines( tt, scale(PCs[,1]))
par( oma=c(0,0,0,0), mar=c(5,5,2,2))
axis( 1)
mtext(side=1, line=3, text="Years")
}
Here's the plot:
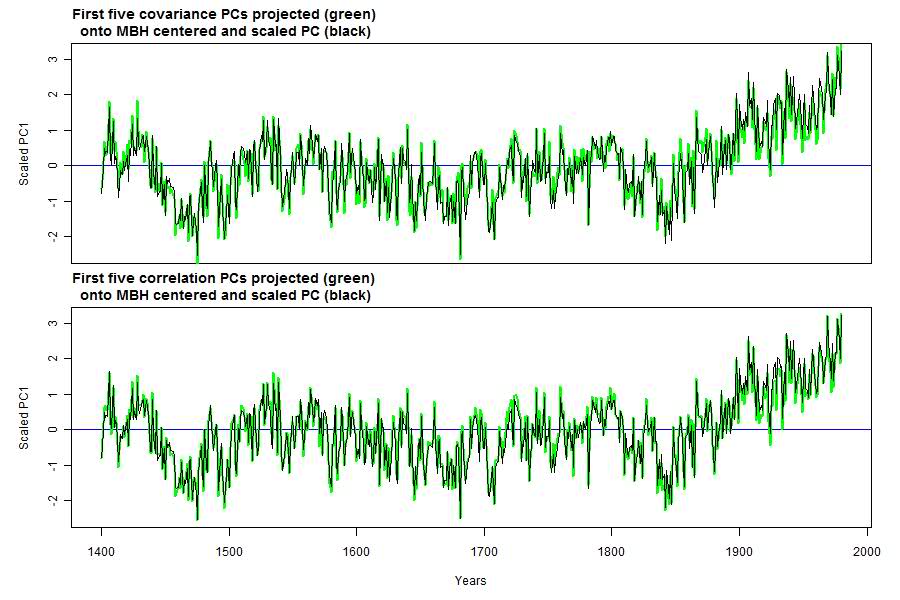 I'll comment more on the results in the next post, and also look in more detail at the various PC's. |












Nick,
ReplyDeleteWhat do you think of McIntyre's "Texas Sharpshooter" criticism?
http://climateaudit.org/2008/08/08/caspar-ammann-texas-sharpshooter/
Well, that's calibration/verification, which is a stage before PCA, and the decentered scaling as computed here. It's one of the things I'd like to look at, though when I downloaded the more complete W&A files which do this but, the filenames don't match up. I'm trying to fix that. But I would like to get to the bottom of the r2/RE story.
ReplyDeleteThe CA post is so full of snark it's quite hard to follow.
All the graphs are cut off at about 1750 on my computer and your last sentence ends as "...and also look in more detail at the".
ReplyDeleteEverything else seems to be fine, though.
Perhaps it's the IE8 I'm using ? (Not by choice : I'm at work)
JM,
ReplyDeleteIt depends on what magnifications you're using. In Firefox ctrl+ expands, ctrl- reduces, If you reduce, you'll see more.
Or you can just double click on the fig, and it will go to full screen.
The y-axis is in units of 'standard deviation from the mean'?
ReplyDeleteRon,
ReplyDeleteYes - "scaled" means mean 0 sd 1.
Nick,
ReplyDeleteThis is indeed timely. The exclusion of substantive discussion of Wahl and Ammann from the Wegman report was a particularly egregious example of a clear pattern of bias.
Indeed, the Wegman report studiously avoided any discussion of PC retention/selection criteria, even though this is an essential step in any PCA.
W&A state:
"When proxy PCs are employed, neither the time period used to “center” the data before PC calculation nor the way the PC calculations are performed significantly affects the results, as long as the full extent of the climate information actually in the proxy data is represented
by the PC time series. Clear convergence of the resulting climate reconstructions is a strong indicator for achieving this criterion."
In W&A, is there a test of the PC set to determine how many are required to ensure that they represent the "full extent of the climate information actually in the proxy data [subset]". Or are PCs added to the overall temperature reconstruction until the convergence indicator is achieved?
Thanks, Deep. I'm looking forward to getting further into this. What do you think of Smith's "elementary" paper?
ReplyDeleteAt first glance it looks like it misses crucial aspects of the MBH98/99 methodology, although it's a reasonable description and discussion of one of the steps (calculation of the set of PCs for dimensionality reduction of the North American tree-ring proxy network at the 1400 step).
ReplyDeleteI'm not clear how this is tied to his discussion about the overall reconstruction though. It doesn't appear to me that Smith explains how these particular PCs were actually used in the overall reconstruction. Yet it appears he is comparing a reconstruction based on this sub-network (which was only used as *part* of the 1400-1450 portion only within the MBH overall calibration/reconstruction) directly to the overall MBH reconstruction.
But I will read it again when I have more time. I could well have missed something.
Also - one thing you should look at is the percentage "explained variance" in each PC. To do that of course you need to calculate all the PCs, but I think princomp will return the all the data you need.
ReplyDeleteYou will find that the standardized SVD methods (whether short-centred or not) have more "explained variance" in each of the leading PCs than the MM method on the correlation matrix.
I don't get it. Smith says:
ReplyDeleteIn particular, M&M (2005a) showed that the
version of PC analysis used by MBH was more or less the following:
1. A data source was compiled that, for this discussion, is taken as 70 tree-ring series for 1400-1980.
...
6. Finally, PC1 was rescaled so that the mean was 0 and the variance 1 over 1902-1980. This was the displayed result.
That's simply not the way MBH98 was done. And I don't think M&M said that it was either (although they did miss key aspects of the MBH methodology, notably PC selection/retention criterion).
Bottom line: The PCs generated by Smith are not directly comparable to the MBH reconstruction even in the 1400-1450 portion, let alone the whole period!
Or am I missing something? You tell me.
Corrected - you could delete the immdeiately previous one.
ReplyDeleteI screwed up my terms above. The point is MM used unstandardized PCA (covariance matrix) with proper centering and MBH used standardized (correlation matrix) short-centred.
W&A also tested a third combination centred, standardized PCA.
My point is that standardized PCs will have greater explained variance in the leading PCs, regardless of centering used. That's why you need fewer PCs to represent the data set and achieve convergence.
Also:
ReplyDeleteIn the calibrations step The North American tree ring PCs are regressed against HadCRUT global tempearture!!??
Deep,
ReplyDeleteThanks for the comments - I'm fairly new to this, and some of the RC stuff (esp PC1) seemed odd, though I found his discussion helpful.
I'm interested in the variance explained aspect - the discussions I've heard had PC's swapping order rather easily, which I guess means there is a layer of fairly equal middle rankers.
I'd hoped to have made more progress, but I've been distracted by Jeff's GCM thread (not to mention Wegman). Still, I've learnt something about GCM's. Maybe this weekend.
I deleted your comment as suggested.
I suppose my concluding remark about Richard Smith's paper is that he should refocus explicitly on just the NA tree-ring reduction step for 1400-1450 or 1400-1500 (which in effect is what you are doing, even though you are showing the entire PC) or else completely revise his reconstruction implementation and go with a simplified version of the overall MBH methodology, as W&A did. Note that the latter choice means using additional proxy series even for 1400-1500, as well as a more sophisticated calibration than Smith used (i.e. PCA of the instrumental temperature, not just calibrating against the global series).
ReplyDeleteOr do both - showing the different reconstructions if one uses just the available data back to 1400 vs the more complete MBH reconstruction.
It would be extremely helpful if folks would actually read MBH98, which addresses all the points I've raised.
http://www.meteo.psu.edu/~mann/shared/articles/mbh98.pdf
For example:
We isolate the dominant patterns of the instrumental surface temperature data through principal component analysis (PCA). PCA provides a natural smoothing of the temperature field in terms of a small number of dominant patterns of variability or ‘empirical eigenvectors’. Each of these eigenvectors is associated with a characteristic spatial pattern or empirical orthogonal function’ (EOF) and its characteristic evolution in time or ‘principal component’ (PC).
as long as you are deleting DC comments
ReplyDelete"This is indeed timely. The exclusion of substantive discussion of Wahl and Ammann from the Wegman report was a particularly egregious example of a clear pattern of bias."
The paper Nick is discussing is a 2007 paper. .
Perhaps Wegman has a bias against time travel. or perhaps DC was referring to an earlier paper. Not sure, which is it?
Steven,
ReplyDeleteWegman was asked about the W&A paper. Here's the excerpt:
[Bart Stupak] Did you analyze this work by Wahl and Ammann prior to sending your final report to the Committee on Energy and Commerce? If so, why does
your report not alert the reader that these researchers had conducted a reanalysis of the MBH98 that corrected the only statistical methodology error discussed in the "Finding" section of your report and that these researchers found that recentering the data did not significantly affect the results reported in the MBH98 paper?
{Wegman] The Wahl and Ammann paper came to our attention relatively late in our deliberations, but was considered by us. Some immediate thoughts we had on Wahl and Ammann was that Dr. Mann lists himself as a Ph.D. coadvisor to Dr. Ammann on his resume. As I testified in the second hearing, the work of Dr. Ammann can hardly be thought to be an unbiased independent report.
W&A 2007 was accepted, in press and available online in early 2006, more than four months before the release of the Wegman Report. It was even referenced in the much earlier NRC Report. Yet Wegman also claimed that this was not a "peer-reviewed, published" article. This is highly misleading, as the article had not been published in print, but was in press, and most certainly was peer reviewed. Unlike Wegman et al.
ReplyDeleteIn press is not "published". you may think they should have reviewed it, fine. But in press not equal to published. In press means going to be published.
ReplyDeleteThere is no relevant distinction between "in press" and "published." That is, unless paper adds credibility to work, in which case there's always the print button.
ReplyDeletecce said "There is no relevant distinction between "in press" and "published." That is, unless paper adds credibility to work..."
ReplyDeleteI believe that is wrong, and the previous comment that "in press" means "going to be published" is accurate. "published" can include publishing online. The Wahl and Ammann paper "Robustness of the Mann, Bradley, Highes reconstruction ..." that I assume is being referred to was in fact not published online until 31 August 2007. So, contrary to deepclimate's assertion, Wegman's claim in mid 2006 that the Wahl and Ammann paper was not a "peer-reviewed, published" article appears to have been fully accurate, and not "highly misleading".
I think the technicality about in press/published is unimportant here. The issue is that W&A had done what Wegman should have done - a repeat of the MBH analysis without the flaws that he complains of. It was available to him, and was known to have passed peer review and been accepted by the editors.
ReplyDeleteIf he had really been trying to inform Congress about the state of scientific knowledge re MBH, he should have discussed what W&A actually said, rather than avoiding it with date technicalities or waving it away as somehow tainted by Ammann's connection with Mann. It's relevant statistical analysis, and deserves to be treated as such.
"It was available to him, and was known to have passed peer review and been accepted by the editors."
ReplyDeleteActually, I would even say "in press" is one step beyond "accepted". There was an "accepted" version available quite a bit earlier IIRC. Both the "accepted" and "in press" versions were available online.
The only reason it wasn't "published" at the time, is that the official date of publication is that of the print version. "Online publication" usually refers to cases where there is no print version.
Face it - W&A addressed all the issues that Barton staffer Peter Spencer wanted to be avoided. How anyone can justify the exclusion of W&A, which discusses actual stistical issues, and yet support the bogus (and non-statistical) social network analysis is beyond me.
Correction - the previous acceptance was "provisionally accepted". I believe that was in September 2005.
ReplyDeleteThe full history reads:
Received: 11 May 2005 / Accepted: 1 March 2006 / Published online: 31 August 2007
But, anyway, it's not disputed that actual publication was later. But that's no excuse to exclude it. And Wegman et al's excuse appears to imply that it hadn't been peer reviewed yet - that is absolutely and categorically false.
We know that Barton staffer Peter Spencer sent Wegman et al an M&M presentation as part of the initial "package" of background info, presumably the May 11 2005 George Marshall presentation. We also know that Spencer updated Wegman et al with the fact that NCAR had declared M&M's critiques fully answered, based on the NCAR press release of MAy 11 2005, announcing Wahl and Ammann's paper.
Now what do you think the chances are that Spencer actually sent a link to the actual paper at any time?
TCO, I don't see how you can possibly defend this behaviour. Wegman said it was not a "published refereed paper", strongly implying that it had not been peer-reviewed, and that pending publication was a valid reason to exclude it.
The bottom line is that all three peer-reviewed critiques of M&M were deliberately excluded from substantive discussion. That is inexcusable. Get over it.
And did you notice how Wegman cherry-picked the parts of W&A he thought supported him, and misrepresented the central findings?
Yes, indeed, my post on Wegman's trick to hide Wahl and Ammann is long overdue. Unfortunately there is so much else wrong the Wegman report that it's hard to find the time.