It's a long post, so I'll include a table of contents. I want to start from first principles and make some math connections. I'll use paler colors for the bits that are more mathy or that are just to make the logic connect, but which could be skipped.
- Basics - averaging temperature and integration
- Averaging and integration.
- Integration - theory
- Numerical integration - sampling and cells
- Triangular mesh
- Integration by function fitting
- Fitting - weighted least squares
- Basis functions - grid
- Basis functions - mesh
- Basis functions - spherical harmonics
- Basis functions - radial basis functions
- Basis functions - higher order finite element
- Next in the series.
Basics - averaging temperature.
Some major scientific organisations track the global temperature monthly, eg GISS, NOAA NCEI, HADCRUT 4, BEST. What they actually publish is global temperature average anomaly, made up of land station measurements and sea surface temperatures. I write often about anomalies, eg here. They are data associated with locations, formed by subtracting an expected value for the time of year. Anomalies are averaged; it isn't an anomaly of an average - a vital distinction. Anomalies must be created before averaging.I also do this, with TempLS. Global average anomaly uses two calculations - an average over time, to get normals, and an average of anomalies (using normals) over space (globe). It's important that the normals don't get confounded with global change; this is often handled by restricting the anomaly to a common base period, but TempLS uses an iterative process.
Averaging and integration.
People think of averaging as just adding N numbers and dividing by N. I often talk of weighted averaging - Σ wₖxₖ / Σ wₖ (x data, w weights) Dividing by the weights ensures that the average of 1 is 1; a more general way of implementing is just to divide by trhe result of applying what you did to x to 1.But the point of averaging is usually not to get just the average of the numbers you fed in, but an estimate of some population mean, using those numbers as a sample. So averaging some stations over Earth is intended to give the mean for Earth as a whole, including the points where you didn't measure. So you'd hope that if you chose a different set of points, you'd still get much the same answer. This needs some care. Just averaging a set of stations is usually not good enough. You need some kind of area weighting to even out representation. For example, most data has many samples in USA, and few in Africa. But you don't want the result to be just USA. Area-weighted averaging is better thought of as integration.
Let me give an example. Suppose you have a big pile of sand on a hard level surface, and you want to know how much you have - ie volume. Suppose you know the area - perhaps it is in a kind of sandpit. You have a graduated probe so that you can work out the depth at points. If you can work out the average depth, you would multiply that by the area to get the volume. Suppose you have a number of sample depths, perhaps at scattered locations, and you want to calculate the average.
The average depth you want is volume/area. That is what the calculation should reveal. The process to get it is numerical integration, which I'll describe.
Integration - theory
| A rigorous approach to integration by Riemann in about 1854 is often cited. He showed that if you approximated an integral on a line segment by dividing it into ever smaller segments, not necessarily of equal size, and estimated the function on each by a value within, then the sum of those contributions would tend to a unique limit, which is the integral. Here is a picture from Wiki that I usd to illustrate.
The idea of subdividing works in higher dimensions as well, basically because integration is additive. And the key thing is that there is that unique limit. Numerically, the task is to get as close to it as possible given a finite number of points. Riemann didn't have to worry about refined estimation, because he could postulatie an infinite process. But in practice, it pays to use a better estimate of the integral in each segment. |  |
Riemann dealt with analytic functions, that can be calculated at any prescribed point. With a field variable like temperature, we don't have that We have just a finite number of measurements. But the method is the same. The region should be divided into small areas, and an integral estimated on each using the data in it or nearby.
The key takeaway from Riemann theory is that there is a unique limit, no matter how the region is divided. That is the integral we seek, or the volume, in the case of the sand pile.
Numerical integration - sampling and cells
The idea of integation far predates Riemann; it was originally seen as "antiderivative". A basic and early family of formulae is called Newton-Cotes. Formulae like these use derivatives (perhaps implied) to improve the accuracy of integration within sub-intervals. "Quadrature points" can be used to improve accuracy (Gauss quadrature). But there is an alternative view more appropriate to empirical data like temperature anomaly which is of inferring from sample values. This acknowledges that you can't fully control the points where function values are known.
So one style of numerical integration, in the Riemann spirit, is to divide the region into small areas, and estimate the integral of each as that area times the average of the sample values within. This is the method used by most of the majors. They use a regular grid in latitude/longitude, and average the temperatures measured within. The cells aren't equal area because of the way longitudes gather toward the poles; that has to be allowed for. There is of course a problem when cells don't have any measures at all. They are normally just omitted, with consequences that I will describe. GISS uses a variant of this with cells of larger longitude range near the poles. For TempLS, it is what I call the grid method. It was my sole method for years, and I still publish the result, mainly because it aligns well with NOAA and HADCRUT, also gridded.
Whenever you average a set of data omitting numbers representing part of the data, you effectively assume that the omitted part has the same behaviour as the average of what you included. You can see this because if you replaced the missing data with that average, you'd get the same result. Then you can decide whether that is really what you believe. I have described here how it often isn't, and what you should do about it (infilling). Here that means usually that empty cells should be estimated from some set of nearby stations, possibly already expressed as cell averages.
This method can be re-expressed as a weighted sum where the weights are just cell area divided by number of datapoints in cell, although it gets more complicated if you also use the data to fill empty cells (the stations used get upweighted).
While this method is usually implemented with a latitude/longitude grid, that isn't the best, because there is a big variation in size. I have explored better grids based on mapping the sphere onto a gridded Platonic polyhedron - cube or icosahedron. But the principle is the same.
Triangular mesh
My preferred integration has been by irregular triangular mesh. This recent post shows various meshes and explores how many nodes are really needed, but the full mesh is what the usual TempLS reports are based on. The msh is formed as a convex hull, which is what you would get if you drew a thin membrane over the measuring points in space. For the resulting triangles, there is a node at each corner, and to the values there you can fit a planar surface. This can be integrated, and the result is the average of the three values times the area of the triangle. When you work out the algebra, the weight of each station reading is the area of all the triangles that it is a corner of.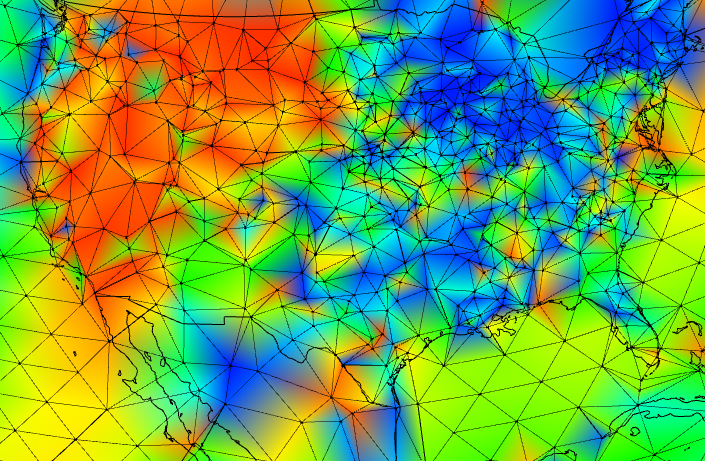
Integration by function fitting
There is a more general way of thinking about integration, with more methods resulting. This is where the data is approximated by a function whose integral is known. The usual way of doing this is by taking a set of basis functions with known integral, and linearly combining them with coefficients that are optimised to fit.You can think of gridding as a special case. The functions are just those that take constant value 1 on the designated areas. The combination is a piecewise constant function.
Fitting - weighted least squares
Optimising the coefficients means finding ones that minimise s a sum of squares of some kind of the differences between the fit function and observed - called residuals. In math, that isS = Σ wₖrₖrₖ where residual rₖ = yₖ-Σ bₘfₘ(xₖ)
Here yₖ and xₖ are the value and location; fₘ are the basis functions and bₘ the coefficients. Since there are usually a lot more locations than coefficients, this can't be made zero, but can be minimised. The weights w should again, as above, generally be area weights appropriate for integration. The reason is that S i a penalty on the size of residuals, and should generally be uniform, rather than varying with the distribution of sampling points.
By differentiation,
∂S/∂bₙ=0= Σₖ Aₖₙwₖ(yₖ-ΣₘAₖₘbₘ) where Aₖₙ=fₙ(xₖ)
or Σₘ AAₘₙ bₘ = Σₖ Aₖₙyₖ, where AAₘₙ = Σₖ AₖₘAₖₙ
In matrix notation, this is AA* b = A*y, where AA = ATA
So AA is symmetric positive definite, and has to be inverted to get the coefficients b. In fact, AA is the matrix of scalar products of the basis functions. This least squares fitting can also be seen as regression. It also goes by the name of a pseudo-inverse.
This then determines what sort of basis functions f should be sought. AA ia generally large, so for inversion should be as well-conditioned as possible. This means that the rows should be nearly orthogonal. That is normally achieved by making AA as nearly as possible diagonal. Since AA is the matrix of scalar products, that means that the basis functions should be as best possibe orthogonal relative to the weights w. If these are appropriate for integration, that means that a good choice of functions f will be analytic functions orthogonal on the sphere.
I'll now review my various kinds of integration in terms of that orthogonality
Basis functions - grid.
As said above, the grid basis functions are just functions that are 1 on their cells, and zero elsewhere. "Cell" could be a more complex region, like combinations of cells. They are guaranteed to be orthogonal, since they don't overlap. And within each cell, the simple average creates no further interaction. So AA is actually diagonal, and inversion is trivial.That sounds ideal, but the problem is that the basis is discontinuous, whereas there is every reason to expect the temperature anomaly to be continuous. You can see how this is a problem, along with missing areas, in this NOAA map for May 2017:
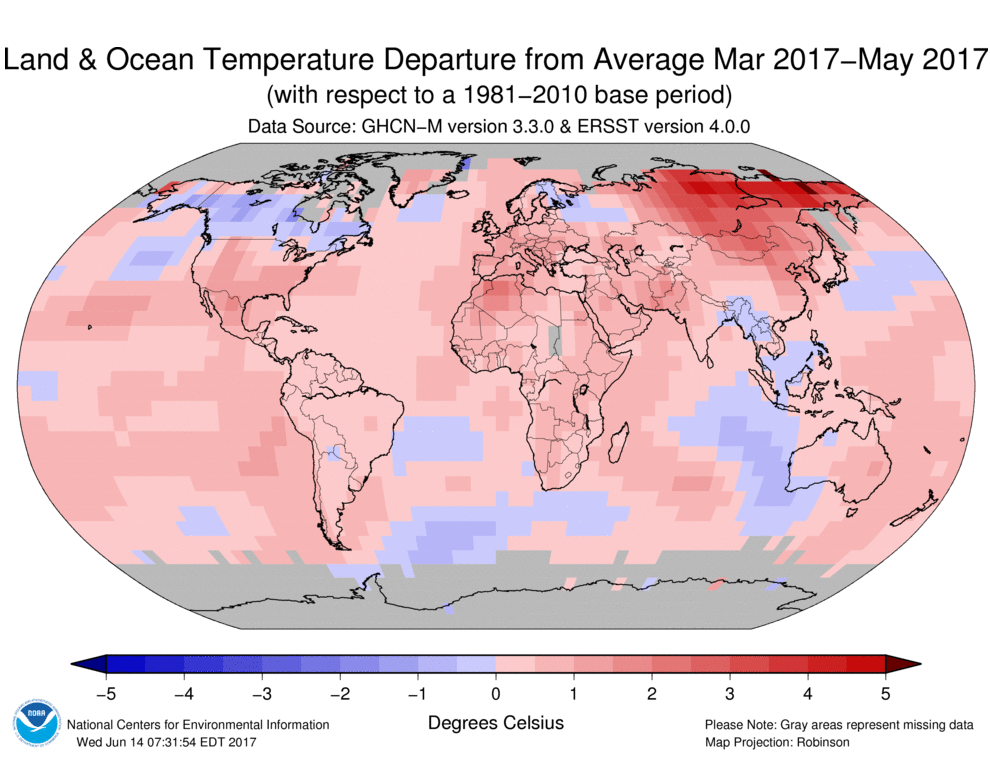
I described here a method for overcoming the empty cell problem by systematically assigning neighboring values. You can regard this also as just carving up those areas and adjoining them to cells that do have data, so it isn't really a different method in principle. The paper of Cowtan and Way showed another way of overcoming the empty cell problem.
Basis functions - mesh.
In this case, the sum squares minimisation is not needed, since there are exactly as many basis functions as data, and the coefficients are just the data values. This is standard finite element method. The basis functions are continuous - pyramids each with unit peak at a data point, sloping to zero on the opposite edges of the adjacent triangles. This combination of a continuous approximation with a diagonal AA is why I prefer this method, although the requirement to calculate the mesh is a cost. You can see the resulting visualisation at this WebGL page. It shows a map of the mesh approximation to TempLS residuals, for each month back to 1900.Basis functions - spherical harmonics.
This has been my next favorite method. Spherical harmonics (SH) are described here, and visoalised here. I compared the various methods in a post here. At that stage I was using uniform weights w, and even then the method performed quite well. But it can be improved by using weights for any integration method. Even simple grid weights work very well. After fitting, the next requirement is to integrate the basis functions. In this case it is simple; they are all zero except for the first, which is a constant function. So for the integral, all you need is the first coefficient.I also use the fit to display the temperature field with each temperature report. SH are smooth, and so is the fit. Here is a recent example:
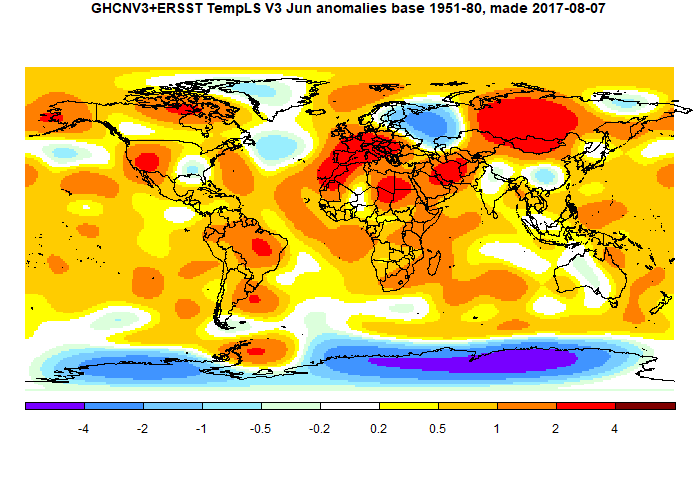
This is the first case where we have a non-trivial AA to invert. I tend to use 100-200 functions, so the matrix can be inverted directly, and it is very quick in R. For a bigger matrix I would use a conjugate gradient method, which would be fine while the matrix is well-conditioned.
But it is conditioning that is the limitation. The basis functions have undulations, and at higher order, these start to be inadequately resolved by the spacing of data points. That means that, in terms of the approximate integration, they are no longer nearly orthogonal. Eventually AA becomes nearly singular, which means that there are combinations that are not penalised by the minimising of S. These grow and produce artefacts. SH have two integer parameters l and m, which roughly determine how many periods of oscillation you have in latitude and longitude. With uniform w, I can allow l up to 12, which means 169 functions. Recently with w right for grid integration, I can go to 16, with 289 functions, but with some indication of artefacts. I'll post a detailed analysis of this soon. Generally the artefacts are composed of higher order SH, so don't have much effcet on the integral.
Basis functions - radial basis functions.
This is a new development. RBFs are functions that are radially symmetric about a centre point, and fade from 1 toward 0 over a distance scaled to the spacing of data. They are smooth - I am using gaussians (normal distribution), although it is more common to use functions that go to zero in finite distance. The idea is that these functions are close to orthogonal if spaced so only their tails overlap.It's not necessarily much different to SH; the attraction is that there is flexibility to increase the spread of the functions where data is scarce.












Nick -- I read through the comments ('discussion') at Climate Audit. Your patience with the pseudoskeptic crowd is already legendary; this only adds to it. Jankowski and Browning in particular would have received nothing but a standard reply from me --- "Hey dipsh*t, get back to me after you buy a clue."
ReplyDeleteBrowning obviously knows some physics or math, or did at one time.
DeleteHe made this statement:
"Ken,
I have given a simple mathematical proof on this site that using forcing on a set of time dependent partial differential equations one can obtain any solution one desires. Christy has stated that he looked at 102 models and none agreed well with the obs. All missed the 1998 El Nino high. Now the modelers are going to adjust (tune or change the forcing) of the models to better agree with the obs. If you know the answer, it is not a problem to reproduce the result.
Jerry"
This is true to various degrees, as a transfer function is a differential equation, and one can pass an input that can match any output you want. In many cases, it has nothing to do with the differential equation selected.
Consider ocean tides, which obey Laplace's tidal equations, which are a set of differential equations. It turns out those act as a rather benign transfer function, and the output is best approximated by a set of sinusoidal functions corresponding to the known lunisolar diurnal and semidiurnal cycles. For a tidal analysis, the solution is matched to the output and that is a generally accepted approach.
So there are a huge range of differential equations that someone can apply to a problem, but if the output approximately matches the input, that's the case that Browning is talking about. But I am not sure if he understands that.
Browning can't accept that this works for the spatial integration that Nick is working out.
WHUT
Delete"Browning obviously knows some physics or math, or did at one time."
Yes, but he gets an awful lot of elementary stuff wrong. Even in your quote:
"All missed the 1998 El Nino high."
Climate models are never expected to predict that. Models do do ENSO, which is rather a miracle, but they don't come with any phase relation to Earth history. That would be true even if they were initialized to recent data, which they aren't.
Of course climate models should be able to predict the 1998 El Nino high. From my response to Browning above, the key is to consider that natural variability is a transfer function mapping the forcing inputs to the geophysical response. These are considered temporal boundary conditions, not initial conditions.
DeleteConsider these two well-known mechanisms:
1. Everyone understands that the seasonal cycle is a deterministic response from solar input to the output. That gives the intuitive hot/cold cycle we all can intuit.
2. Same thing with tidal response, which is a deterministic response from lunisolar input to the output. No one has any doubts over that forcing mechanism either.
So you can see that these aren't initial conditions, but temporal boundary conditions that guide the solution to maintain a consistent phase with the forcing.
But what no one has ever done is to map the combined seasonal and lunisolar inputs as input to the geophysical ocean. All the fundamental equations are discussed in the ENSO literature, such as the delayed differential and Mathieu equations -- ready to be tested.
If you do that -- forcing the equations with the calibrated lunar and solar modulation, any reasonably long ENSO interval can be used to predict any other interval.
The issue with people like Browning perhaps is that they are mathematicians first and only applied physicists second. They never tried the obvious mechanism to start with and so went down a rabbit-hole of increasing complexity, with their frustration of not being able to model anything boiling over into a contrarian rage that we see on social media.
Same thing with Richard Lindzen and his inability to model QBO. He never understood the physical mechanism behind QBO and so created his own mathematical world of complexity. I believe his lashing out at climate science is a defense mechanism or projection of his own inability to do the science correctly.
In contrast, most mainstream scientists are not filled with the rage that Browning and Lindzen can barely contain. They are willing to let scientific progress play out without interference.
WHUT - applying percentages to absolute temperature makes absolutely zero sense unless one is using Kelvin. Even after Nick pointed this out they stuck to their guns. Kelvin temperatures are directly proportional to the molecular energy; 100 K has half as much motion-energy per molecule as 200 K.
ReplyDeleteUsing other scales you have nonsense like this:
__ Kelvin Celcius Fahren Delisle
t1 287.65 = 14.5 = 58.1 = -78.25
t2 288.65 = 15.5 = 59.9 = -76.75
Pct change
__ 0.347% _ 6.89% _ 3.098% _ -1.917%
Also the inability to see that uncertainties for anomalies are less than the uncertainties for absolutes. These are concepts that 14 or 15 year olds should be able to quickly understand.
Re: ENSO - Have you established that current GCM designs allow for the lunar/tidal influences that appear to determine ENSO can be properly incorporated? If not, you're expecting the impossible from current designs and what you really want is a complete redesign to allow this to be. Yes, we all want a pony. It's not an excuse to give Jankowski and Browning a free pass.
Laplace's tidal equations are at the root of all computational climate models. The derivation hierarchy is like this: Navier-Stokes -> Primitive equations -> Laplace's tidal equation. This is from most general to a linearization.
DeleteWhat people don't appreciate is that the tidal equations aren't actually used for analyzing tides. No redesign of GCMs is necessary.
So this analysis is completely orthogonal to the application of GCMs. Indeed, if the GCM's were parameterized to predict tides, it would be overkill. Tides are a geophysical phenomenon separate from the details of circulation models. Therefore, tidal sea-level height anomalies don't come out of the GCM output. And it would be surprising if it did, because the lunar parameterization is nowhere to be seen in the input.
What I am doing with the ENSO model is similar to this. ENSO is not a circulation, it is a geophysical tidal effect that is at a different scale than what GCM's are looking at.
And then consider QBO, which is subject to the same Laplace's tidal equations. When Richard Lindzen first tried to understand QBO, he went down a rabbit-hole of complexity in regards to the equations. In fact, there is a way to solve the LTE analytically by making a few assumptions based on the symmetry of the equator (along which the QBO arises).
DeleteOnce that is out of the way, if we input the cyclic lunar nodal tidal forces precisely, then the characteristic QBO cycle with all its fine detail is reproduced accurately. Its actually very automatic.
In contrast, if you look at the research literature, it's known that GCMs will not reproduce the QBO behavior out of the box. On occasion one will find a paper that claims to match QBO behavior by tuning a GCM model. But these rely on a natural atmospheric resonance that occurs only if specific parameters are set. Again, they have no lunar tuning available because those parameters are not even in the code base.
NASA JPL has internal research proposals that anyone can look at which suggest that much more climate behavior is forced by the moon than anyone in "consensus" circles is willing to consider.
Browning and company are a lot like Lindzen in that they are barking up the wrong tree. It's really not about being unable to solve complex numerical equations, but of getting the geophysics right and finding the simplest formulation whereby the observed behavior emerges.
So its basically all talk and no walk on their part.
Nick.
ReplyDeleteNice summary!
I am convinced that you can't really do better than a triangular mesh of the actual measured temperatures. Least squares fitting always means assuming some underlying continuous function of temperature.
Grid averaging over a fixed time interval is better suited to study regional scale spatial resolution. However, here again Icosahedral grids rather than (lat,lon) grids are best, because they avoid unequal area biases.
PS. If there is a TOA energy imbalance, then Teff must reduce.
Thanks, Clive,
DeleteTriangular mesh is still my preferred option too. I'd like to find something that is different but nearly as good, for comparison.
I've been doing more with icosahedral grids, and I'll write about it soon. It's along the lines of the cubed sphere here. It's the same idea that I can make a package of the nodes and their relations for various subdivisions, suitable for routine use - then you don't really need to worry about the geometry any more. But the cubed sphere is pretty good too, and I spent some time getting an equal area version, eg here.