It solves the problem of overfitting - having more proxies than years of measurement of target temperature. But it also has limitations. It can't make use of local temperature information. The notion of standard deviation is not really appropriate, since neither proxies nor the target temp are stationary random variables. And, as normally implemented, proxies that show little temperature dependence are swept in, and add only noise.
It's a convenient method to analyze, so I thought I would study the effect of selection of proxies by correlation in the calibration period - recently controversial. Not too much should be made of it, since selection is motivated by avoiding overfitting, which is not a problem in CPS. But I'm developing the methods for use in more complex algorithms.
Pseudo-proxies
Pseudo-proxies are created by taking some computed temperature curve going back centuries. Here I use output from CSM from 850AD to 1980, as described in Schmidt et al. Then noise is added. It could be red noise thought to be characteristic of real proxies, but for present purposes, to focus on analytic approximation, I'll use white noise.So the N proxies are formed:$$P_i=F_i*T+W_i,\ \ i=1...N$$
T is the target temperature, f is a constant factor (S/N) for each proxy and W the noise. I'll assume for arithmetic simplicity that both P and T are normalized relative to the calibration period, and I'll use a symbol \(\cdot\) to indicate a dot product mean over the years of that period.
Math of CPS
So with the normalization, all that is needed is to take the mean of the proxy construction:$$p=f*T+w,\ \ i=1...N$$ where p,f,w are the mean over proxies of P,F,W. The mean p will still have zero mean, though not unit SD; the averaging will reduce the noise by a factor of about √N.Then f is estimated by regression in the calibration period:$$\hat{f}=p\cdot T/T\cdot T=p\cdot T$$ So the recon $$\hat{T}=\frac{p}{p\cdot T}$$
Now using our special knowledge of proxy structure, $$p\cdot T=f+w\cdot T$$ so $$\hat{T}=\frac{f*T+w}{f+w\cdot T}$$ or with \(e=w/f\) $$\hat{T}=\frac{T+e}{1+e\cdot T}$$
So this is in principle a nearly unbiased estimator. e should have zero mean, and the expected value of \(e\cdot T\) should also be zero. Let's see how that works out.
Example
I created 59 proxies as described. The factors F, which are approx the S/N) were randomly generated in a range from 0.03 to 0.18. Once generated these factors were kept constant through the analysis. Unit white noise was added and the result normalized.I'll show first the temperature, with calibration period in red. There's not much point in showing a bare proxy - it just looks like noise.
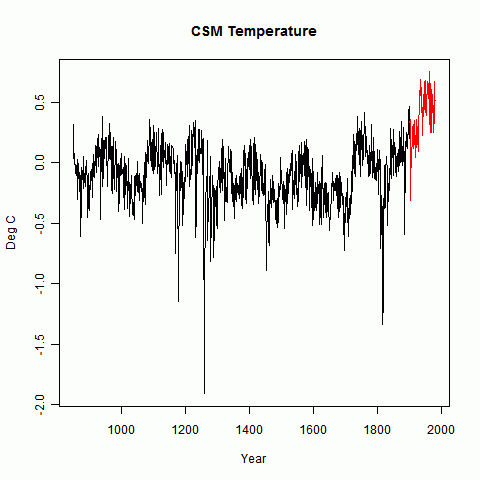
The next plot shows, in red, the CPS recon as described above. The green is an "unbiased" recon where T has the corresponding amount of white noise added.
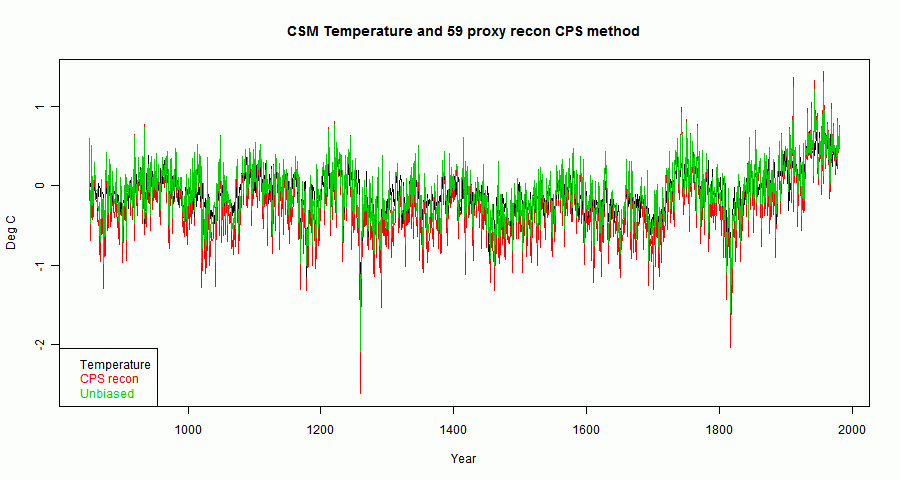
Noise is dominant, but the HS shape is there, reflecting the way the proxies were constructed. A smoothed curve will show any biases better (emphasising them greatly relative to the noise):
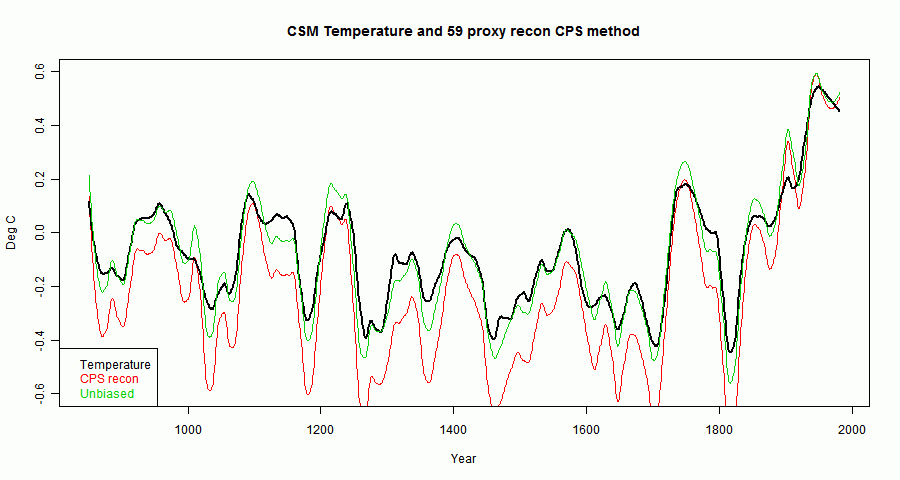
Update. I originally had colors wrong on the legend. To fix this, I did a new run. As I say below, the apparent "bias" can go either way - in the earlier plot it was above by a large margin; this time it's below. I've changed the relevant numbers.
There is a small apparent bias in the scale factor which multiplies the green curve to get the red. This is the \(1+e\cdot T\) denominator and can go either way. In this case, the se for this is about 0.14 about a mean of 1. In fact in this realization it was 0.83, which is on the low side.
There is an actual bias, because of the non-linear operation of inversion. However, in this case it is only about 0.02 - ie 2% difference.
Selection
So now what happens if a subset of proxies is chosen according to the correlation in the calibration period? The correlation, with above normalizing and notation, is:$$\rho_i=P_i\cdot T = F_i+w_i\cdot T$$
The intent of selection is to choose for high S/N - ie F. But the selection cannot distinguish between ρ that is high for this reason or high because of the second factor - a chance alignment of noise with T in the calibration period. One of these will persist pre-cal, the other probably will not.
Note that this effect is dependent on the distribution of F values. If they are all equal - a common choice for toy examples - then the effect is maximised, because selection is purely on the random alignments of w and T. And if the S/N is low, again random will dominate. But if there is a subset with high S/N, then selection for these will work as intended, and create little bias.
So in the recon, the denominator \(1+e\cdot T\) no longer has expected value 1, and so is a source of genuine bias. Let's see how that works out, choosing the top 24 by calib ρ out of the 59:
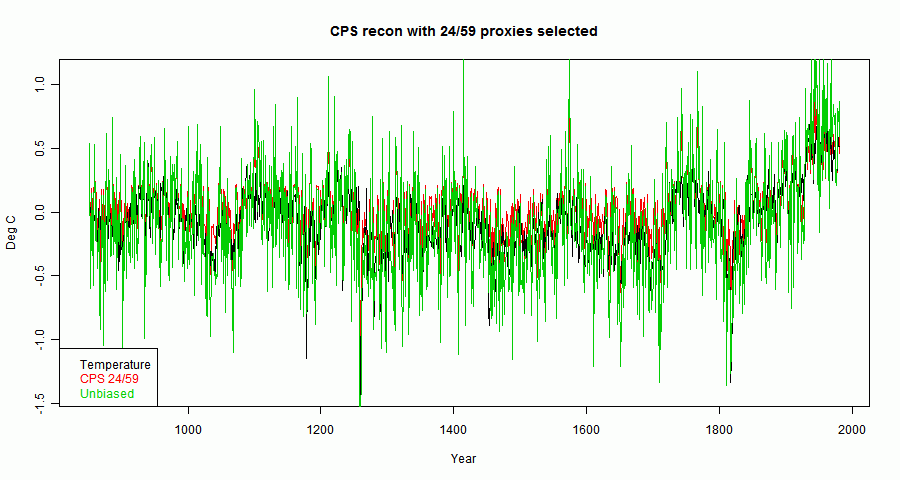
You can see that the red now lies abobe the black and green, clearer in a smoothed plot:
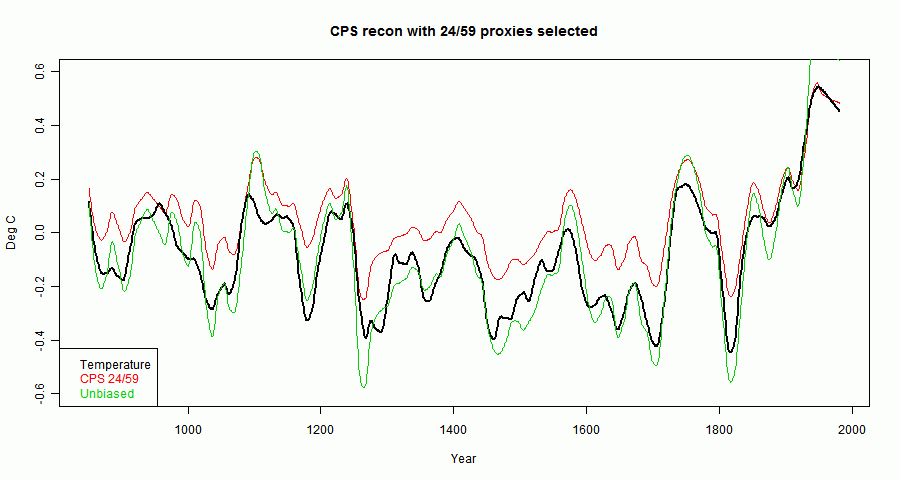
In fact, the denomninator \(1+e\cdot T=1.66\) which is the source of the bias.
Implication
Having identified the source of the bias, it would be nice to be able to correct for it. However, the denominator involves f which is the very thing we are after.The main thing to say is that for CPS, the only case analyzed here, the effect is not so important, because selection by correlation after normalization is not usually done. A variant which may be of some importance is where a correlation-weighted sum of proxies is used.
Code is here












Nick, I'm looking at your expression for T-hat. It appears to me it won't be unbiased. The denominator term drive it low for large N.
ReplyDeleteIf you use few proxies, you are dominated by the measurement uncertainty (the first order terms in "e" aren't negligible), In other words, your source of proxies (Schmidt) isn't useful for studying this problem, because there are simply way too proxies to overcome the variably between proxies.
Regarding: "The denominator term drive it low for large N."
ReplyDeleteLet me say I don't know whether it will drive it low without doing any math or simulations. That was speculative and in retrospect I have a 50/50 chance..
I'm almost certain for large N (large number of proxies), you'll find a net bias in T-hat.
Carrick,
DeleteAs I mentioned, there is a bias from the denominator arising from the second term in the Taylor series expansion. In this example, it's less than 2%.
I didn't use the Schmidt proxies, being now uncertain of which temperature they are based on.
Nick, sorry I missed the part about not using their proxies. But the issue I was raising was whether you've used a large enough N to accurately measure the bias not the particular source of the proxies, I would simply say 59 certainly isn't enough.
ReplyDeleteUsing just N=59, you won't have verified convergence of T-hat (unless "e" is very small, which isn't realistic here).
Hi Nick, Just a question about your code.
ReplyDeleteIn this line:
## S/N ratios for 59 proxies
fp=0.15*c(0.993,1.186,1.166,0.624,1.046,1.094,0.337,0.871,0.816,0.452,0.782,0.202,0.363,0.677,0.213,0.32,0.956,0.403,0.575,0.345,0.563,0.651,1.133,1.033,1.069,0.903,0.65,0.911,0.832,0.841,0.206,0.533,0.986,0.421,0.884,0.557,1.165,0.348,0.553,0.961,0.818,0.894,0.719,1.181,0.314,0.932,0.558,1.031,0.623,1.16,0.441,1.056,0.282,0.735,0.237,0.509,0.548,0.581,0.559);
You are hardwiring the S/Ns for the proxies.
That isn't really in the spirt of a Monte Carlo is it?
Carrick,
DeleteAs I said in the text: "The factors F, which are approx the S/N) were randomly generated in a range from 0.03 to 0.18. Once generated these factors were kept constant through the analysis."
It's not meant to be a MC on S/N. If I do it again, I'll just use a regular sequence of S/N.
I noticed your latest comment at Lucia's about getting new proxies. The reality here, as I've ascertained, is that with this level of noise, selection just isn't working. That is, it isn't selecting High F values preferentially at all (well, not noticeably). Instead, it selects on random alignment, which then produces bias. The S/N in this toy example is mush lower than in real studies.
Hey, when's the next TEMPLS coming out? Everybody seems to be late this month... MEI is up again so global temps should keep rising through at least September...
ReplyDeletehttp://www.esrl.noaa.gov/psd/enso/mei/table.html
It's been too hot ... no, I can't use that excuse here. Hopefully within a couple of hours.
Delete