As I noted in the previous post, a new post has appeared at WUWT which talks a lot about the reduction in station numbers in GHCN that occurred between about 1990 to present. This post is based on a paper by Ross McKitrick.
The stream of articles that advance various theories about this reduction don't take proper account of the way GHCN was actually compiled. It was initially a historical process, where in the early 90's with grant funding people gathered together batches of historic records, recently digitised, into a database. After V2 came out, in 1997, at some stage NOAA undertook the task of continuing monthly updates from CLIMAT forms. This made it, for the first time, a recurrent process.
Update: Carrot Eater, in comments, has pointed to a very useful and relevant paper by Peterson, Dann and Phil Jones. As he says, the process wasn't quite as I've surmised. I should also have included a reference to Peterson's overview paper.
The big reduction followed changes of policy in going to a recurrent process. As a batch process, it didn't really matter if the geographic spread was uneven. If the records were available, they could be included. But as a recurrent process, it makes sense to spread the effort of updating reasonably evenly worldwide.
If you look carefully at the time sequence of station terminations, it looks like this:
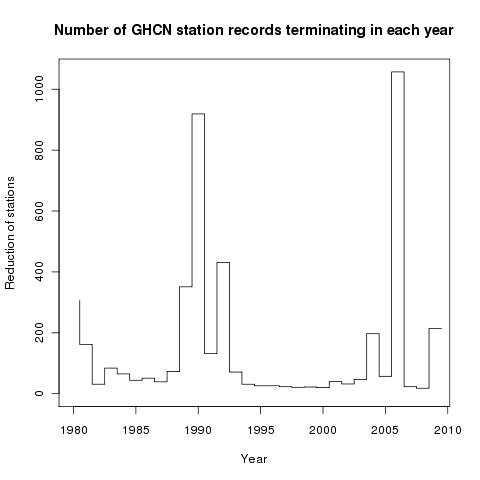
It clearly consisted of a few major culling events. In the next table, the years with more than 100 stations ending are shown with a breakdown by country:
 |  |
 |  |
 |  |
 |
This makes the pattern clear. Australia, Canada, China, S Africa, Turkey and USA had been overrepresented, and were culled in specific events. Canada in 1989/90, Turkey and China 1990, S Africa 1991, Australia 1992 and the USA in 2004 and 2006. The case of the US is special, because the USHCN database is also used.
So when it is said that the reductions produced a reduction in average altitude or latitude, that reflects the fact that some of these countries are relatively high, and are (mostly) from temperate latitudes.
Of course, explaining how and why the reduction happened doesn't remove the possibility of biasing a trend estimate. That's another story.












I think you're slightly off on some details, or wording at least.
ReplyDeleteThe paper you want is
http://www.ncdc.noaa.gov/oa/hofn/gsn/gsnselection.pdf
This paper describes how they chose their ideal network of stations, back in 1997. But note that, to a large extent, they chose the stations that were already reporting CLIMATs on a monthly basis anyway. At the time, something like 1500 or 1600 stations were sending CLIMATs.
So I don't think anything was culled, in that somebody told the individual countries to stop sending CLIMATs for 5000 stations. Rather, they never even started sending CLIMATs for all those stations in the first place. So you'd have to go back to what instructions were given back when the CLIMAT format was put together - did countries just pick their own stations, or did the WMO suggest some? I don't know that.
As for latitude bias: has McKitrick figured out yet that the high latitudes (at least NH) warm faster than low latitudes? And has he figured out yet that with gridding, it doesn't matter so long as each grid cell remains decently sampled (which is not always the case, admittedly)? I haven't bothered reading his tome, but when this is the upshot, one suspects.
Anyway, anybody working with the GHCN should know to include the USHCN if he's worried about sampling, or rural coverage, in the US. In that respect, the 2004-2006 dropout doesn't actually exist.
Nick,
ReplyDeletePass my little paper on Altitude to carrot if he would like to comment before I post.
Carrot, if you like, have a read and criticize.
CE,
ReplyDeleteThanks for that Peterson paper link. It is very relevant. Although "culling" isn't the right word (and it's a notion I've been deprecating anyway) I think the observations on country specifics stand.
And Steven, although Blogger asks for email addresses from commenters, I don't seem to have access to them (or I haven't found it). Would it be OK to put a copy for CE on your doc drop?
Nick:
ReplyDeleteOf course, explaining how and why the reduction happened doesn't remove the possibility of biasing a trend estimate. That's another story.
It would only have an effect if the drop in stations resulted in an undersampling of a region. This is probably the case for the loss of stations in at higher latitudes. I don't believe there is a "cure" for undersamping that doesn't include imposition of a model to infill lost/missing regions.
Carrot Eater: As for latitude bias: has McKitrick figured out yet that the high latitudes (at least NH) warm faster than low latitudes? That's true as a generalism, but coastal stations might warm less quickly than interior ones in the northern arctic for example. Remember that SST won't exhibit much/any high latitude amplification. I'd think the exception would be the high arctic (> 80°N, Goddard's favorite place in the world) where a long-term trend in ice loss, should have an impact on long-term trend.
"As for latitude bias: has McKitrick figured out yet that the high latitudes (at least NH) warm faster than low latitudes?"
ReplyDeleteI think you should ignore the latitude bias analysis as it stands. It seems Ross hasn't figured out that you need to strip the signs off the latitudes before averaging. So in his analysis when you remove Arctic stations the average lat goes down, but if you remove Antarctic stations, it goes way up!
In fact I found that the stations are bunched in temperate latitudes, and the average abs latitude is quite stable.
... wow.
ReplyDeleteThat's special.
So not only is the average latitude in itself irrelevant (as gridding makes it irrelevant), but he messed up in calculating it.
There's always something comedic in people wrongly calculating the wrong number.
and eh? what is this I'm supposed to be reading? I'd normally be happy to review something, but I've not got free time nowadays.
Nick Stokes: I think you should ignore the latitude bias analysis as it stands. It seems Ross hasn't figured out that you need to strip the signs off the latitudes before averaging
ReplyDeleteNorthern and southern hemisphere latitudinal effect aren't symmetric, so, no, I can't agree with this argument. It's a simply wrong way to do the average.
If I were to say McKitrick got anything really wrong, it was in not area-weighting his average. Most of the effect disappears when you do an area-weighted average (post 1950).
My latitudinal average is performed using the published CRUTEM3 perl scripts, btw. Here is my resulting estimate of the bias in CRUTEM3 trend estimate.
ReplyDeleteThis bias is in land-surface only, with a 0-bias representing an Earth which is entirely covered with land (so the ~8% bias seen post-1950 is "real", it represents a real bias in land-mass towards the northern hemisphere.)
It suggests that the trends are affected by only a few percent by adding/dropping stations since 1950. It's also interesting that it suggests that part of the 1925-1950 "warming period" might be artifactual.
Carrick,
ReplyDeleteThese are interesting bias calcs - could you say a bit more about how you derived them?
I agree that NH, SH aren't symmetric, but averaging signed latitude is a much more serious error.
Anyway it's moot now, because Ross has an updated version which corrects the errors with GHCN-adj and uses abs value of latitude.
Ross did use a kind of area weighting for latitudes, which I didn't understand and thought was doubtful. I didn't query it because the sign was a more serious issue. I expect some kind of weighting would be appropriate - I just don't know what it should be.
I think one should look for a latitude bias in the distribution of empty grid cells. Normalised for the land area in each latitude band. Meaning, start with seeing what is entirely unsampled, before moving on to figuring out what is undersampled, which is a more substantial work (and had been attempted different ways before McKitrick ever showed up with this).
ReplyDeleteAnd keeping NH and SH separate the whole way, as is standard practice for this sort of thing.
NIck, as to how I did my calculations, basically I downloaded the subset of the CRU data set (land only of course). I then ran station_gridder.perl to generate the averaged cells. Letting theta be the latitude I used this formula to calculate the mean latitude of the cells:
ReplyDeleteformula
Here N(theta) the number of non-zero cells at a given latitude.
Because there is a bias to land in the Northern hemisphere, you expect the mean latitude to be around 17° or so. The gradual shift towards that value represents the fill-in of missing stations from Southern regions.... Of course early series were dominated by US and Europe, as the southern climes started reporting data, we see a shift to a more
If you look at my previous graph of latitudinal trend... there is almost no effect in the Southern hemisphere, until you get to extreme southern regions, for which there is very little land area (and hence almost no weight to a global average from this). Adding on dropping stations isn't expected to generate much of a bias for the Southern hemispheric average.
Neither averaging theta nor absolute value of theta is perfect (using theta understates the effect of dropped Northern stations, so replacing latitude with absolute value isn't a fix. Carrot's observation that one should split North and South is a much better solution.
But in either case, mean latitude not used in calculating the bias, so neither theta nor absolute value of theta is "wrong" (but I'm confused about what you actually learn from |theta|).
The way I compute the bias in trend estimate is to assume that the dominate bias in bias is latitudinal. So I define a function Lambda:
Lambda(theta1,theta2) = Tdot(theta1, theta2)/ Tdot(-pi/2, pi/2)
Tdot is the temperature trend over a range bounded by times t1, t2 (I used Jan 1, 1960 to Dec 31, 2009). It is produced using CRU's algorithm, which is to average the temperature for a given time over all non-zero cells using a simple cos(theta) weighting function.
Here is what lambda looks like.
Lambda is a sort of teleconnections function that relates how global temperature varies to the local temperature trend.
Here's what I came up with:
Computation of Tbias
(Note I'm really using the density of stations N(theta)/N_total. The term on the bottom left is computing N_total. It's unnecessary to introduce Lambda of course, this is just left over terminology from another discussion.)
Of course when I say "temperature" I mean "temperature anomaly."
ReplyDeleteNick,
ReplyDeleteI've sent you a new version with your analysis and Zeke's and I re did mine entirely when I found the thing I found.. hehe.
Ross got a bucnh wrong about the march of thermometers. Its really something you would never imagine.
Anyways, if CE wants to read it and get his 2 cents in. he can email me.
Lastname; mosher
Firstname: steven
Domain:.gmail.com
paste(Lastname,Firstname,domain, sep="")