The issue is a claim that a common practice of making a last-stage proxy selection by observed correlation with temperature in the calibration period (when instrumental readings are available) constitutes a "selection fallacy". I made myself unpopular by asking just what that is - the response seemed to be that I'd been told and anyway any right-thinking person would know.
But there have been attempts to demonstrate it, with varying effects, and whatever the "fallacy" was, it seems to be shrinking. Lucia says now that she doesn't object in principle to selecting by correlation; only to certain methods of implementing. There was an interesting suggestion at CA from mt to use MSE rather than correlation for selection.
Roman's CA example, linked above, was held to show a selection bias. But it turned out that there is in his CPS method a bias from the limited number of proxies, and selection by correlation had no more evident effect than random selection. He then gave another example with white noise and more proxies with higher S/N which did seem to show some selection effect.
Anyway, I've been doing some tinkering with methods, which I'll describe.
Proxy reconstruction
For general information about proxy methods, I've been referring to the NRC CommitteeNRC North Report. I find this a useful source precisely because it is a panel effort, with a contribution and review from noted statisticians (who did not seem to notice a "selection fallacy"). The basic task is to get as many proxies as you can, form some sort of average and scale it to temperature. The scaling necessarily involves a correlation with some measure of instrumental temperature. Proxies are any observed property of which you have a long and dateable history, which you expect to be primarily influenced by temperature in a relation that could be expected to have endured.An obvious problem with averaging the proxies is that they may be diverse properties, even with different units. One method, popular in times past, is CPS, which normalizes and averages. Normalizing means to scale with zero mean and unit variance.
A problem with this, not so often noted, is that the proxies are not stationary random variables, for which a notion of variance makes sense. They do, or should, echo temperature (which also gets normalized), and this has a strong secular trend, at least recently. Normalizing sounds normal, but it is weighting. Since it usually involves dividing by the sd taken over all available time, that weighting does involve peeking at the period of time for which you want results. In particular, it downweights proxies that show variation due to features like the MWP.
A less obvious problem is overfitting. There is a century or less of annual data available, and this may well be less than the number of proxies you want to scale. CPS, which reduces to one series, was favored because of that. Selecting proxies by correlation also counters overfitting.
In my view, the first method of aggregating considered should be to scale the individual proxies by imputed temperature. You can do this by some kind of regression against temperature in the overlap period. I believe this is what Gergis et al did, and it requires that you find a statistically significant relation to proceed. IOW, selection by correlation not only reduces overfitting, but is required.
Carrick noted a very recent paper by Christiansen and Ljungqvist 2012 which follows this method. In this post I experiment with that method.
Regression issues
Since you eventually want to determine T from P (proxy value), it might seem natural to regress T on P. This is CCE (Classical Calibration Estimator). But people (eg MBH 1998) use inverse calibration (ICE) of P on T, and C&L recommend this as being more physical (P is (maybe) determined by T).It makes a difference. Since P and T are both subject to what is normally modelled as error, when you choose one as the regressor, the combined error tends to be attributed to the regressand. So CCE tends to inflate the variance of T, and ICE tends to deflate it. But the method normally invoked here is EIV - Errors in Variables.
EIV can be pretty complex, but there is a long-standing one-regressor version called Deming regression (not invented by Deming). The key problem is that you want to find a line that minimises least square distance from a sctter of points, rather than distance ot one of the axes. The problem is, that line depends on the axis scaling. In Deming regression, you scale according to the estimated variance of each of the variables.
Deming formulae
We need to regress over a calibration period. I'll use subscript cal to denote variables restricted to that period. For the i'th proxy, let$$xm=mean (T_{cal});\ \ x=T_{cal}-xm$$
and
$$ym=mean (P_{cal});\ \ y=P_{cal}-ym$$
We need the dot products
$$sxx=x\cdot x,\ \ sxy=x\cdot y,\ \ syy=y\cdot y$$
Finally, we need an estimate of the variance ratio. I could use $$d=syy/sxx$$. That actually greatly simplifies the Deming formula below - the slope reduces to \(\sqrt(d)\). However, because x and y aren't anything like stationary, they should at least be detrended to estimate d. I prefer to subtract a smoothed loess approximant (f=0.4); it generates a ratio of high frequency noise, but at least it seems more like noise.
Then the Deming formula for slope is
$$\hat{\beta}= w+\sqrt{w^2+d},\ \ \ w=(syy-d*sxx)/sxy/2$$
and the best fitted T is
$$T=xm+(P-ym)/\hat{\beta}$$
Note that I've dropped the cal suffix; this is the best fit in the calibration, with the formula extended.
Noise
The results without screening, in the example below, seem very noisy. The reason is that when correlation is low, the slope is poorly determined. My next exercise will probably be to weight according to regression uncertainty. But for the moment, I'll stick with screening as a method for reducing noise.Example
I'm using Roman's example data. This consists of CSM modelled temperature with 59 proxies (850-1980) taken from a paper by Schmidt et al, with realistic noise added to the modelled temperature. A 26 Mb zipped datafile is here.The selected group were those with correlation exceeding 0.12. There were 24. I also included a non-selected group of 24 (proxies 10 to 33).
Fig 1 shows the temperature in the screening period, which like Roman I took to be 1901 to 1980.
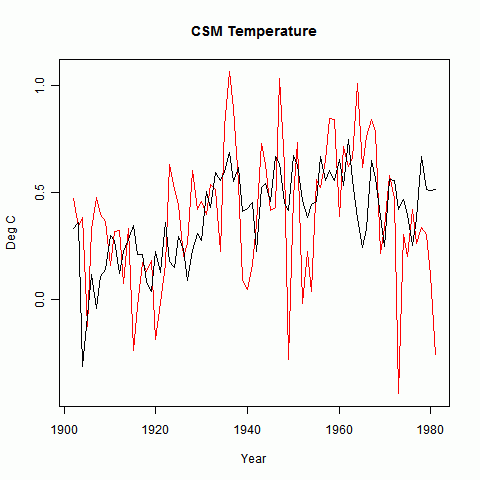
Fig 2 shows the full reconstruction. It mainly shows that the selected group came out somewhat higher, and the full proxy set is very noisy.
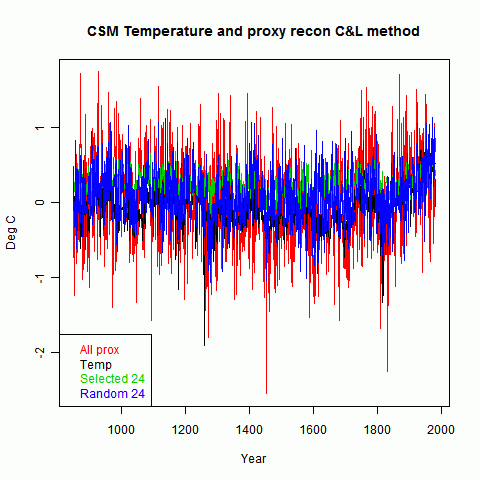
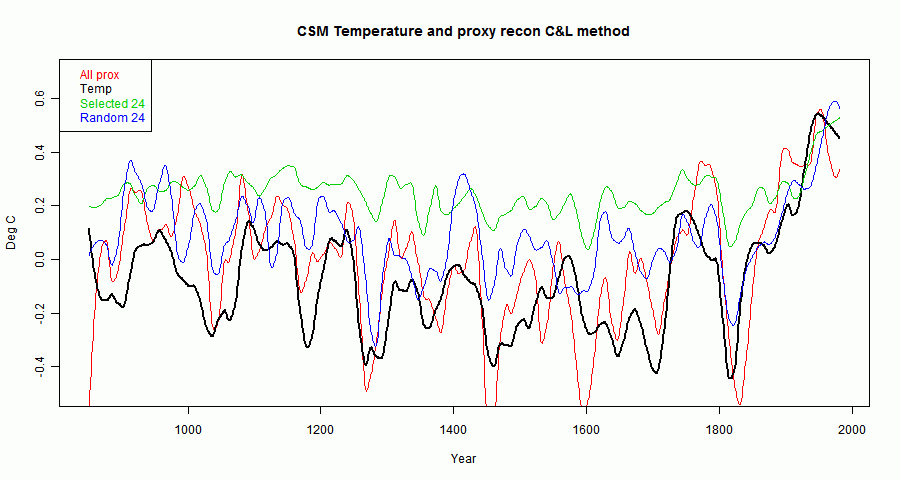
Fig 3 shows the reconstruction, but using Roman's smoother. It makes things clearer. The unscreened versions seem relatively unbiased but noisy. The screened version looks rather like Roman's CPS version, and has slightly smaller MSE (0.17).
I'll post the code tomorrow. This post is technically somewhat interim - I want to explore the effect of weighting according to regression uncertainty.
Update - code is here












Interesting Nick. I think the focus on screening by correlation has lead to progressive methods that neatly avoid problems with it. I think the main focus for anybody using correlation for screening is it isn't necessarily a statistically neutral operation, and secondly weighting with finite weights that are based on correlation could still introduce bias..
ReplyDeleteFigure 3 is interesting to me. One quick think to look at is, the correlation between the reconstructed and original temperature series over the reconstruction period. What is needed is a method for computing the change in SNR as you change the selection criteria. Correlation is one method for that. If you want to eyeball the SNR in a visual plot, it'd probably be better to rescale the series that have obviously large scaling biases, then match them to common baseline (e.g., mean = 0).
The main crux of my kitchen remodel should be through this morning, so I should have time to play with some of my ideas again. As I've mentioned, I think the bias in the random selection arises from a bias introduced by non-white noise in the fitted slopes. This is easy to check by using "true" white-noise proxies and may be a place where regressing on slope along with the AR(1) coefficient (for example) might reduce some of the bias.
Carrick,
ReplyDeleteI think one of the points we have both been making is that if screening causes bias, weighting should too.
A reason I like this approach is that it focusses on the primary things you have - the correlation between individual P's and T. It may be necessary for stability, overfitting etc to average down, but that's the base information you have. So an algorithm based on it shows what you're losing (and gaining) by averaging, as in the forms of CPS.
I can't at the moment see how that non-white noise bias would happen, but it's true that Roman's white proxies enhanced the contrast of selection.
Hi Nick,
ReplyDeleteThere's apparently a relationship that holds for the harmonic mean of a series of positive numbers x1, x2, x3, ..., it is basically:
x_h ≤ x_a
where x_h = harmonic mean and x_a is the arithemetic mean, and the equally holding only when all of the values are equal. Here's a link.
Basically this means if you invert the slope of the scaling relationship between temperature and the proxy, you are guaranteed to get loss of variance.
I agree with your other comment, I've said for a while that selection by correlation screening is just a special case of weighting proxies by correlation. It's just the special case W = 0 and W = 1.
I should have added ... you are guaranteed to get a loss of variance unless you have very noisy data.
ReplyDeleteNick,
ReplyDeleteI haven't the time or inclination to read through all the comments on Roman M's post.
But it seems to me there was another big problem with his screening procedure that I'm not sure was addressed.
AFAIK, the Mann-Schmidt pseudo-proxies were generated by adding noise to the *local* temperature reconstruction in a set of randomly selected grid cells. Therefore a proper screening test would screen them the same way, no? That is, the screening should have use the corresponding local temperature reconstruction in the instrumental period (or else the actual local instrumental temperature). That is how Mann et al 2008 screened, BTW.
This probably also explains why the screening correlations were so low.
A second issue is that these pseudo-proxies were generated with a set noise parameter, and so all should have been more or less somewhat correlated to their local grid temperature. To test screening procedures, the pseudo-proxies should be generated with differing amounts of noise, to see if screening would improve the reconstruction method in this case, by selecting the less noisy pseudo-proxies.
Deep,
DeleteI have been looking into the origins of the pseudo-proxies, so far with nothing conclusive. But yes, I think from the description it's likely local temperatures were used, Roman seems to have treated them as homogeneous, noise plus NH-CSM.
I'm not sure that screening on local temps would have made a big difference to what Roman was demonstrating. It wasn't really to screen efficiently, but to show that it caused a bias. In fact, he didn't really show that - the bias increase was only what you'd extect from the reduced numbers. Maybe a local-temp based screen might have produced a greatly different subgroup of 24, which might have shown more bias.
I think Roman's CPS is anyway too far from what Gergis et al were doing.
I think we may be in violent agreement, judging from your newest post (so I'll go there next).
Delete1) Selection bias issues should be tested using pseudo-proxies generated from the *same* temp reconstruction as being used for regression cutoff selection.
2) A more realistic exploration of these issues would also use varying S/N pseudo-proxies within the same test set (in contrast to the original Mann et al 2007 study, which was actually comparing CPS and EIV methods using pseudo-proxy sets of uniform S/N at various levels).