Station-based monthly global temperature indices use gridding at some stage, and usually the grid cells follow some regular rule, like a lat/lon square. This causes some problems:
|  |
The purpose of gridding
The naive way to get a world average temperature anomaly is just to add results for all the stations. But it gives wrong results when stations are concentrated in certain regions. And it underrates SST.The usual way is to create a regular grid, and in some way average the readings in each cell. Then an area-weighted mean of those cell averages is the result.
This gives a fairly balanced result, and has the same effect as numerical surface integration, with each grid a surface element, and the integrand represented by the cell average.
TempLS does something which sounds different, but is equivalent. It forms a weighting based on inverse cell density, expressed in each cell as cell area divided by the number of data points in the cell.
Another way of seeing that is to imagine that the cell was divided into equal areas, one containing each cell. Then the weights would be just those areas.
Empty cells
Empty cells are usually just omitted. But if the temperature anomaly averaged over just the cells with data is presented as the global average, necessarily some assumption is implied as to their values. If you assumed that each missing cell had a value equal to the average of the cells with data, then including them would give the same answer. So this can be taken to be the missing assumption.
Is it a good one? Not very. Imagine you were averaging real temperature and had a lot of arctic cells empty. Imputing world average temperatures to them is clearly not good. With anomalies the effect is more subtle, but can be real. The arctic has been warming more rapidly than elsewhere, so missing cells will reduce the rate of apparent warming. This is said to be a difference between Hadcrut, which just leaves out the cells, and GISS, which attempts some extrapolation, and gets a higher global trend. GISS is sometimes criticised for that, but it's the right thing to do. An extrapolated neighbor value is a better estimate than the global average, which is the alternative. Whatever you do involves some estimate.
Irregular cells and subdivision
Seen as a surface integral approx, there is no need for the cells to be regular in any way. Any subdivision scheme that ascribed an area to each data point, with the areas adding to the total surface, would do. The areas should be close to the data points, but needn't even strictly contain them.Schemes like Voronoi tesselation are used for solving differential equations. They have good geometric properties for that. But here there is a particular issue. There are many months of data, and stations drop in and out of reporting. It's laborious to produce a new mesh for each month, and Voronoi-type tesselations can't be easily adjusted.
Binary tree schemes
I've developed schemes based on rectangle splitting, which lead to a binary tree. The 360x180 lon/lat rectangle is divided along the mean longitude of stations. Then the rectangle with longest side is divided again, along the lat or lon which is the mean for stations in that rectangle. And so on, but declining to divide when too few stations would remain in one of the fragments. "Too few" means 2 at the moment, but could be refined according to the length of observations of the stations. There's also a minimum area limit.
That's done at the start. But as we go through month by month, some of those rectangles are going to have no data. That's where the binary tree that was formed by the subdivision comes in. It is the record of the divisions, and they can be undone. The empty cell is combined with the neighbor from which it was most recently split. And, if necessary, up the tree, until an expanded cell with data is found.
Weights
In binary tree terminology, the final set of rectangles after division are the leaves, and adding a notional requirement that for each month each cell must contain data leads to some pruning of the tree to create a new set of leaves, each being a rectangle with at least one data point. Then the inverse density estimate is formed as before - the cell area divided by the number of data. Those are the weights for that month for each cell.Does it work?
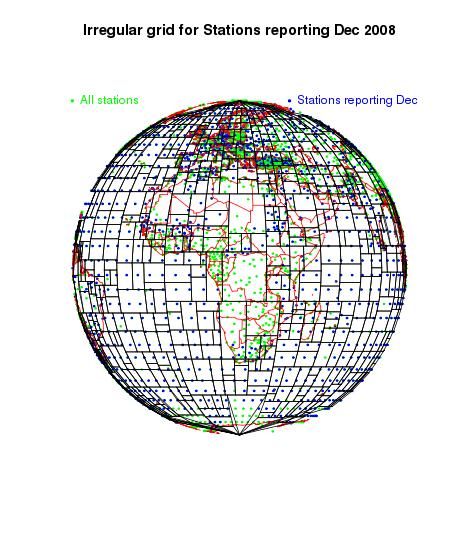
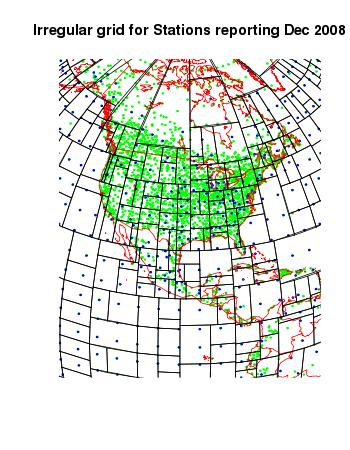
Yes. I've produced a version of TempLS V2 with this kind of meshing. A picture of the adapted mesh for Dec 2008, GHCN, is above. I'll show more.The mesh manipulations, month to month, take time. I've been able to reduce the run time for a Land/Sea GHCN run to well under a minute, but the irregular mesh doubles that. I'm hoping to improve by reducing the number of tree pruning ops needed.
Results
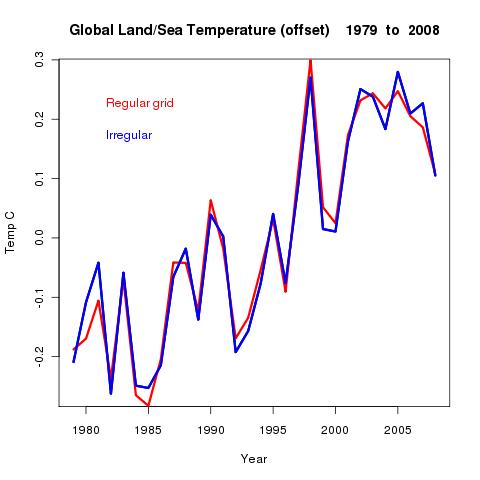
I did a run from 1979 to 2008. Here are the trends using standard TempLS and the irregular grid version. At this stage, I just want to see that the results are sensible.| Trend | Reg_grid | Irreg_grid |
| Number | 9263 | 9263 |
| 1979-2008 | 0.1636 | 0.1584 |
| Trend_se | 0.02007 | 0.02119 |
And here is a superimposed plot of annual temperatures:
 |
So what was achieved?
Not much yet. The last plot just shows that the irregular mesh gives similar results - nothing yet to show they are better. I may do a comparison with GISS etc, but don't expect to see a clear advantage.Where I do expect to see an advantage is with an exercise like the just 60 stations. I think in retrospect that that study was hampered by empty cells. In fact, almost every station had a cell to itself, which meant they were all equally weighted, even though they were not evenly distributed.
Work is needed to adapt the method to region calculations. If the region can be snugly contained in a rectangle, that's fine. But the surrounding space will, by default, be included, which will overweight some elements.
One virtue of the method is that it has something of the effect of a land mask. With a regular grid, coastal cells often contain several land stations and a lot of sea, and in effect, the sea has the land temperature attributed to it. The irregular grid will confine those coastal stations in much smaller cells.
More mesh views
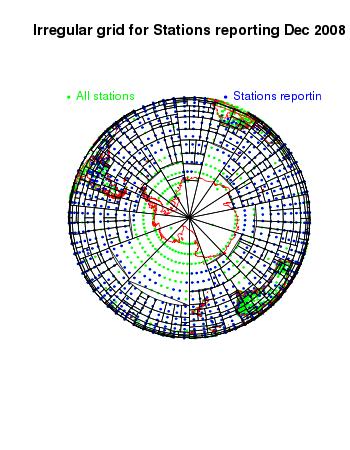
Finally, here are some more views of that mesh used for December 2008:
 |  |
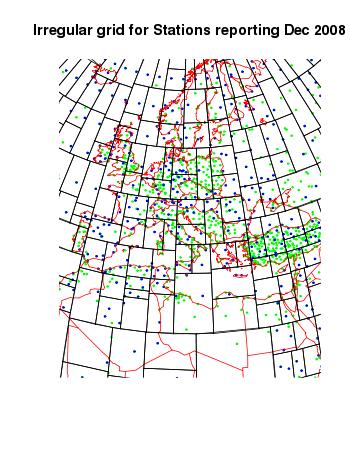
| 
|
 | 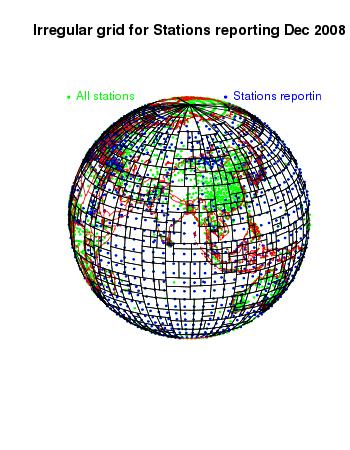 |












Love the gridding diagrams, and the refreshingly novel approach.
ReplyDeleteDo you have any of the gridded datafiles available? I have some code for displaying anomalies for the GISTEMP grid, and it may be fairly easy to make it general enough to display these charmingly irregular grids.
drj, thanks for the comments. I'll put together a file of the data that was used for these plots. Dec 2008 is just one of the months - there is a different (but related) grid for every month.
ReplyDeletedrj, I've put all the data used for these plots on mesh.txt in the zip irreg_grid.zip on the doc store. There is the complete rectangle tree, and a station dataset.
ReplyDeleteIf I might suggest, run a series with a different minimum number of stations for a grid point.
ReplyDeleteThe main issue with minimum number of stations is the correction needed when there is missing data. Usually I ask for 2 or 3 minimum to give a buffer before the search up the tree is needed. But in this case I also set a minimum area, so in dense regions, the number of stations was quite large.
ReplyDeleteI've been experimenting with using a quality score rather than just number. For example, don't divide unless the stations have at least 200 (added) years of record between them.
There was a bug in the program as displayed, in that it didn't guarantee what it was supposed to - that every cell would contain a station in every month. But the exceptions were few, and made no perceptible difference to the analysis. It's fixed now.
The main problem with the concept is that the weighting of cells is locally rather variable. This doesn't cause bias, but does increase noise. It places the major reliance on fewer stations. Existing methods do that too, and it doesn't matter too much, because it mainly affects areas where there are stations to spare. Still, I'm trying to improve that.
Nick, any thoughts on how to estimate the uncertainty with your method?
ReplyDeleteCarrick, it's a linear regression. If you look at the model equations in the next post, after fitting there is a series of residuals, each of which one hopes will behave as an independent random variable, and the variance can be estimated. The variance (and covariance) of the fitted parameters is in turn estimated by applying the inverse design matrix to these variances.
ReplyDeleteOf course, the residuals won't be independent. This has been argued about with the much simpler regression of temp trends (eg Lucia's Cochrane-Orcutt). Here is Joe Triscari (#48938 etc) taking me to task about it in this context. I've been thinking about what might be possible, but it's awkward. I'd need to fit, estimate covariance, then fit again. If I use conjugate gradient, each step has a nested CG iteration.
I've been looking at trying to reduce the uncertainty. Both conventional gridding and my method tend to give quite variable weighting to nearby stations, and this increases variance of the weighted mean. In my pictures this shows up as fluctuating cell areas. Irregular gridding can potentially reduce this variability, by "diffusing" the weighting locally.
Anyway, you've got me thinking about it - I'll try to post some calcs.
Anyway, thanks for your comments. I had seen the exchange with you and Triscari... as you correctly pointed out, his comments on prior art and irregular sampling applies only to 1-dimensional series.
ReplyDeleteTemporal correlation in the residual certainly is a big deal and it will of course affect your estimates of the uncertainty. I have rarely used the uncertainty obtained using the fitting residuals in my estimations of uncertainty. (There are two many assumptions associated with it, stationarity of the noise being a big one.)
In the past, with climate data, I've cheated by detrending and low-pass filtering it in e.g. 30 year segments, which removes all of the correlation. (So on 30 year periods, simple statistical methods apply.)
I also think some noise amplification is a necessary feature of any irregular gridding (whenever you have undersampled regions compared to other more heavily sampled regions). I'll be interested in seeing what you come up with.
My own two cents: I think the best approach for the uncertainty would be a Monte Carlo based approach.
ReplyDeleteBasically you would generate a series of "realizations" of temperature which have the same time/space correlational characteristics. (E.g., high-resolution model outputs.)
Since you know the "actual" global temperature, you can directly measure the error. Repeat this over a number of realizations, and that should allow you to assess the uncertainty associated with your method.
The cool thing about it is you could actually test the effects of different area weightings on your net uncertainty directly.
Re: regional analysis. I think a reasonable method would be to break the world into continents and oceans, and then futher break those down by latitudinal zones. Then apply your gridding algorithm to each area. You could make manual tweaks to accomodate weird/small areas, and set the Arctic and Antarctic as their own areas regardless of continent or ocean. This should make the coverage whithin the gridboxes more uniform, and it would let you to calculate the correlation of anomalies and the uncertainty within each area seperately.
ReplyDeleteCCE, the problem, it seems to me, is that then there would be overlapping areas. With a regular grid you can draw separators, but here with each region having ragged edges that don't fit together, you can't. I'm still not sure how best to grid regions at all. A land mask might help, but it depends on the region.
ReplyDeleteOf course, lat-lon gridding of countries etc also has problems.
You've probably thought about all of this already, but I was thinking that rather than having the algorithm create the grid, you could start with a very tight grid applied uniformly to the whole world. Find the rectangles that best encompass each area and then use your algorithm to subdivide each rectangle, (although keeping to the underlying grid). Then slice off the parts of each rectangle that overlap with other rectangles, keeping to the underlying grid and continent/ocean/zone borders.
ReplyDeleteSome advanced compression techniques slice images into different regions, so they can be compressed according to different criteria. Is there any thing in that field that might apply to this? Your grids certainly look like compressed images, with areas of low and high resolution.
CCE,
ReplyDeleteInteresting ideas. I'm away for a couple more days, so I'll respond more fully when I get back.
Kinda like being mip mapped
ReplyDeletekool work