A few items of news about the interactive climate plotter. Kevin Cowtan, in comments, mentioned that he has been working on a trend plotter for Skeptical Science, and that has now appeared. It emphasises the uncertainties of both trend and intercept, and shows graphically the range of fitted lines. He uses Tamino's near-AR(2) allowance for autocorrelation, which is an advance on the Quenouille adjustment that I used in the trend viewer. The Moyhu climate plotter is restricted to annual data, and so reports much lower significance (though little affected by autocorrelation).
He also has a post here on Hadcrut3, with an emphasis on land/ocean balance (or imbalance) as a source of bias.
The other news is that I've added some new things to the interactive plotter. You can now copy a rather long URL for linking. This will bring up the plotter in the state which you last created.
You can also embellish the plot with a legend and title. There is a current rather bland default title, but you can write your own.
I have also added the interactive plotter and the trend viewer to the permanent pages listed near top right. At some stage I'll reorganise the gallery.
Thursday, March 29, 2012
Sunday, March 25, 2012
Autocorrelation, regression and temperatures
Temperature trends are much discussed, and less frequently their statistical significance. But there is a further question of what statistical significance means. It is tied up with the behaviour of the deviations from the trend, and assumptions that may have been made about them.
This became controversial a while ago with Eric Steig's analysis of Antarctic temperatures. Hu McCulloch wrote an informative post.
I've been thinking more about it as a result of the interactive plotter. I gave estimates for the uncertainty of trends based on OLS assumptions, but foreshadowed a correction for autocorrelation. The usual remedy, at least in climate blogging, is the Quenouille adjustment to dof that Hu mentioned, and which I used in the trend analyzer. But it does not adjust the actual trend, and I've long been curious about its adequacy.
Fortunately, for the interactive plotter I need not have worried. Global temperature data shows strong autocorrelation from month to month, but not much between annual averages, which is what I used exclusively in the interactive plotter. That's not to say that annual averaging is a free gain there - the averaging takes away more significance than autoorrelation correction would have.
In the process of thinking about it, and prompted by some recent comments from Kevin C, I looked at what Grant Foster had done in Foster and Rahmstorf (see Tamino). In the appendix he looks at GISS data from 1975, and somewhat adapts the Quenouille correction to allow for what seems to be more than lag 1 correlation. So I though that would be agood case to work on.
But the residuals may not be unpredictable if you use other information, in particular, neighboring values. If they are correlated with those, then the joint variation has been included in the estimate of residual variance. You have less information than you thought you had.
The proper remedy for this is another stage of statistical modelling. If you have an observed variable y with regressors x, then the residuals are d=y-x.b, where b are the coefficients. Instead of assuming these are independent random variables, we assume that is true of some combination. In an AR(p) model, with a lag operator L, that would mean d ~ Σ ai Li d, i=1...p.
The other thing I do is use a summation convention. I write entities in linear algebra as coefficients with subscripts, and where they are multiplied, if the same subscript appears in two places, it is assumed to be summed over its range - a scalar product. So for example, the matrix porduct of A and B is Aij Bjk. To work out what kind of entity results, you count the unpaired suffices.
dp=yXpibi.
I'll try to keep p,q etc for suffixes over time (many numbers) and i,j,k for suffixes over coefficients (few).
Then with the coupled Ar(p) process we have:
aiLipqyXqjbj~0 a0=b0=-1
To fit, the following sum of squares is minimised:
S=aiLipq yXqjbj anLnpr yXrmbm~0 with a0=b0=-1
which can be rewritten
S=ai an (Lipq yXqj Lnpr yXrm) bjbm~0 with a0=b0=-1
Now this sure looks like a mess of indices, though it would be worse without that compactness. And anyway, computers understand that sort of thing - it's easy to turn into code. But this last rearrangement shows something about the structure. The expression inside the brackets includes all the summations over time. The suffices p,q,r are all paired within that expression. That's all the big computing. What is left is a low order polynomial is the relatively small number of coefficients. That's hard algebra to do by hand, but insignificant computation. For a regular regression it would be a quadratic, and you'd differentiate to get linear equations in the coefficients. Here it's almost the same, thanks to ...
It goes like this. You write down a relation that you want to be true, subject to getting some numbers right:
F(u)=0.
Then you try a set of numbers u0, and find F(u0) is not zero. So you ask, what is the rate of change of F with each of those variables? If it stayed constant, how much total change would take F to zero?
That amounts to writing the first two terms of a Taylor series:
F(u0)+F'(u0)δ u = 0
That's a linear system that you can solve for δu, add the increment to u0, and try again.
When you get close, it converges with fantastic speed - quadratic convergence. Each discrepancy from the final state is the square of the preceding. You go from 10-2 away to 10-4 to 10-8.
What if for some reason you can't differentiate F, or can't invert F'? The latter is common in CFD, where it is apt to be a large sparse matrix. Then you can substitute what you hope will be a good approximation to the inverse of F'. Then you won't get such good convergence; it might not converge at all. Then you have to try for a better approx. But if it does converge, you'll still get the answer exactly right.
Anyway, no such problems here. Just a polynomial, and the result is a small matrix, just 3x3 for linear regression with AR(2).
wrt a:
Eijkmaibkbm =0
and wrt b:
Eijkmaiajbk =0
The E represents that summation in brackets above:
Eijkm=Lipq yXqk Ljpr yXrm
Each equation has all suffices paired except m, so they are vector systems.
That's the F(a,b) of our Newton process. Now to write the update equation:
Fm + Eimjkaibjbk δam + Eijkmaiajbk δbm = 0
I've cheated a bit there - the suffix m actually represents two ranges, and on F is it the accumulation. But it works out easily in practice.
The other method he mentioned was to explicitly calculate the AR(1) auto-correlation matrix, which comes out in powers of r, and invert that. If that is done as stated, it's a much bigger computation. The inverse of that matrix can be better expressed in terms of the lag coefficients of AR(1). That's equivalent to the approach above, which sidesteps actually doing that.
So how would the Quenouille correction have fared? Pretty well. It's worked out from the Lag coefficient listed above, and the factor is 2.621. This would have reduced the t-statistic from 5.366 to 2.047 instead of 2.131. But it wouldn't have picked up the (small) change in slope.
Where there are multiple coefficients, one should show the covariance matrix:
Here is the same set of results for AR(2)
I think that's enough for the moment. I hope I'll next be comparing the GISS calc of Foster and Rahmstorf.
This became controversial a while ago with Eric Steig's analysis of Antarctic temperatures. Hu McCulloch wrote an informative post.
I've been thinking more about it as a result of the interactive plotter. I gave estimates for the uncertainty of trends based on OLS assumptions, but foreshadowed a correction for autocorrelation. The usual remedy, at least in climate blogging, is the Quenouille adjustment to dof that Hu mentioned, and which I used in the trend analyzer. But it does not adjust the actual trend, and I've long been curious about its adequacy.
Fortunately, for the interactive plotter I need not have worried. Global temperature data shows strong autocorrelation from month to month, but not much between annual averages, which is what I used exclusively in the interactive plotter. That's not to say that annual averaging is a free gain there - the averaging takes away more significance than autoorrelation correction would have.
In the process of thinking about it, and prompted by some recent comments from Kevin C, I looked at what Grant Foster had done in Foster and Rahmstorf (see Tamino). In the appendix he looks at GISS data from 1975, and somewhat adapts the Quenouille correction to allow for what seems to be more than lag 1 correlation. So I though that would be agood case to work on.
Regression and significance
Regression finds coefficients which give a best least-squares predictor (from the regressors) of temperature. Best means that you have used all the information you can from the structure of the residuals, which is often described as causing them to be random, but more precisely unpredictable (from the regressors). Then by modelling the residuals as a random process, you can estimate the range of random effect on the coefficients.But the residuals may not be unpredictable if you use other information, in particular, neighboring values. If they are correlated with those, then the joint variation has been included in the estimate of residual variance. You have less information than you thought you had.
The proper remedy for this is another stage of statistical modelling. If you have an observed variable y with regressors x, then the residuals are d=y-x.b, where b are the coefficients. Instead of assuming these are independent random variables, we assume that is true of some combination. In an AR(p) model, with a lag operator L, that would mean d ~ Σ ai Li d, i=1...p.
Notation
I'm going (as with TempLS) to use some non-standard notation. As one simple adaption, instead of expressing a regression as y~x.b, I'll write it as yX.b~0. That adds an extra coefficient b0, which is constrained to be -1 (to keep the sign of the others right). In linear algebra terms, I will be joining the vector of y's to the regressor matrix. It's actually a small change, but will make for neater equations. It's also a good way to write the code. And I'll do the same with the regression of residuals against lags.The other thing I do is use a summation convention. I write entities in linear algebra as coefficients with subscripts, and where they are multiplied, if the same subscript appears in two places, it is assumed to be summed over its range - a scalar product. So for example, the matrix porduct of A and B is Aij Bjk. To work out what kind of entity results, you count the unpaired suffices.
Linear Algebra
So, returning to the lagged regression, we have residualsdp=yXpibi.
I'll try to keep p,q etc for suffixes over time (many numbers) and i,j,k for suffixes over coefficients (few).
Then with the coupled Ar(p) process we have:
aiLipqyXqjbj~0 a0=b0=-1
To fit, the following sum of squares is minimised:
S=aiLipq yXqjbj anLnpr yXrmbm~0 with a0=b0=-1
which can be rewritten
S=ai an (Lipq yXqj Lnpr yXrm) bjbm~0 with a0=b0=-1
Now this sure looks like a mess of indices, though it would be worse without that compactness. And anyway, computers understand that sort of thing - it's easy to turn into code. But this last rearrangement shows something about the structure. The expression inside the brackets includes all the summations over time. The suffices p,q,r are all paired within that expression. That's all the big computing. What is left is a low order polynomial is the relatively small number of coefficients. That's hard algebra to do by hand, but insignificant computation. For a regular regression it would be a quadratic, and you'd differentiate to get linear equations in the coefficients. Here it's almost the same, thanks to ...
Newton-Raphson
Solving non-linear equations. Taught in undergrad courses, but not as much as it should be. In my working life, as a mathematician doing mostly computational fluid dynamics, I've become more enthusiastic about formulating problems as Newton-Raphson. It separates the specification and solution processes in a very systematic way (even if it's linear).It goes like this. You write down a relation that you want to be true, subject to getting some numbers right:
F(u)=0.
Then you try a set of numbers u0, and find F(u0) is not zero. So you ask, what is the rate of change of F with each of those variables? If it stayed constant, how much total change would take F to zero?
That amounts to writing the first two terms of a Taylor series:
F(u0)+F'(u0)δ u = 0
That's a linear system that you can solve for δu, add the increment to u0, and try again.
When you get close, it converges with fantastic speed - quadratic convergence. Each discrepancy from the final state is the square of the preceding. You go from 10-2 away to 10-4 to 10-8.
What if for some reason you can't differentiate F, or can't invert F'? The latter is common in CFD, where it is apt to be a large sparse matrix. Then you can substitute what you hope will be a good approximation to the inverse of F'. Then you won't get such good convergence; it might not converge at all. Then you have to try for a better approx. But if it does converge, you'll still get the answer exactly right.
Anyway, no such problems here. Just a polynomial, and the result is a small matrix, just 3x3 for linear regression with AR(2).
Fitting
So let's write down first the derivative for minimization:wrt a:
Eijkmaibkbm =0
and wrt b:
Eijkmaiajbk =0
The E represents that summation in brackets above:
Eijkm=Lipq yXqk Ljpr yXrm
Each equation has all suffices paired except m, so they are vector systems.
That's the F(a,b) of our Newton process. Now to write the update equation:
Fm + Eimjkaibjbk δam + Eijkmaiajbk δbm = 0
I've cheated a bit there - the suffix m actually represents two ranges, and on F is it the accumulation. But it works out easily in practice.
Other methods
My contention here is that it's not computationally difficult to do the lagged regression. In his CA post Hu mentioned the Quenouille approach, in which you compute the OLS regression parameters, and then the lag 1 autocorrelation coefficient r of the resudials, and then upscale the sum of squares S by the factor (1+r)/(1-r). It sounds simple, but you have to compute all the same sums.The other method he mentioned was to explicitly calculate the AR(1) auto-correlation matrix, which comes out in powers of r, and invert that. If that is done as stated, it's a much bigger computation. The inverse of that matrix can be better expressed in terms of the lag coefficients of AR(1). That's equivalent to the approach above, which sidesteps actually doing that.
Code
I'll show an R code, to demonstrate that the fearsomeness of all those indices melts away in R. It is for linear regression with AR(1) residuals. I have used the vector b for the coefficients of 1,x and lag 1 respectively. x is time in century units.#Read the timeseries data, and select HADCRUT, from Tamino's file
v=read.csv("AllFit.csv")
g=window(ts(v[,8],s=1950,f=12),start=1995,end=2010)
n=length(g); a=NULL
# Make X (yX), the regression matrix with y added. Time in century units
X=cbind(g,1,(1:n-n/2-.5)/1200)
# Add lagged X
Xi=cbind(X[2:n,],X[2:n-1,])
# Form all the scalar products
XXi=t(Xi) %*% Xi
# get the no-lag coefs as starting point
df=solve(XXi[2:3,2:3])
b= c( df %*% XXi[2:3,1],0)
# Newton-Raphson loop
for(i in 1:4){
# Vec of coef products. Xi*b1 are the residuals
b1=c(1,-b,b[1:2]*b[3])
# Derivatives of b2
b2=cbind(0,-diag(3),c(b[3],0,b[1]),c(0,b[3],b[2]))
xb=drop(XXi%*%b1)
# Sum squares of AR(1) residuals
s= sum(b1*xb)
a=rbind(a,c(b[2],b[2]/sqrt(s*df[2,2]/(n-3)),b[3]))
f=b2%*%xb # The N-R function. df is the derivative
df=b2%*%XXi%*%t(b2) +
matrix(c(0,0,xb[5],0,0,xb[6],xb[5],xb[6],0),3,3)
df=solve(df) # Invert derivative matrix
db=-df%*%f # Increment for b
b=b+db
}
colnames(a)=c("Slope"," t-statistic"," Lag Coef")
print(a)
I have another code to do the same with AR(2). It is very similar; XXi just has the extra lag added (3 more columns) and there is one more parameter.
Results
This was set up to test Phil Jones famous musing about whether trend (of Hadcrut, presumably) was significant since 1995. It was obviously borderline, since I think the warm year 2010 made it significant. Anyway, here's the R output:Slope t-statistic Lag coef [1,] 1.087515 5.366499 0.0000000 [2,] 1.098640 8.142446 0.7458062 [3,] 1.131281 2.131303 0.7457651 [4,] 1.131280 2.131154 0.7458062Each line is for one iteration of the Newton-Raphson loop. The first line is the result without allowing for lag correlation. A t-statistic of 1.96 represents 95% confidence, so without correlation it's highly significant. After four steps the iteration has completely converged, and the slightly higher slope is barely significant. The sum of squares of residuals is very much reduced.
So how would the Quenouille correction have fared? Pretty well. It's worked out from the Lag coefficient listed above, and the factor is 2.621. This would have reduced the t-statistic from 5.366 to 2.047 instead of 2.131. But it wouldn't have picked up the (small) change in slope.
Where there are multiple coefficients, one should show the covariance matrix:
[,1] [,2] [,3] [1,] 0.0005335745 -0.0008131155 -0.0000101355 [2,] -0.0008131155 0.2834549756 0.0005744215 [3,] -0.0000101355 0.0005744215 0.0024882463Slope is second, lag the third. There is little cross-covariance, so quoting SE's for individual components is meaningful.
Here is the same set of results for AR(2)
Slope t-statistic SS residuals [1,] 1.087515 5.351488 2.480858 [2,] 1.093019 8.383367 1.021002 [3,] 1.117079 1.595055 1.020994 [4,] 1.117077 1.595150 1.020994Again a slightly different slope (lower), a considerably lower t-statistics, so now not significant at 95%, and a slightly reduced sum of squares of residuals.
I think that's enough for the moment. I hope I'll next be comparing the GISS calc of Foster and Rahmstorf.
Thursday, March 22, 2012
Interactive JS climate plotter (update)
Next in the series of JavaScript/HTML 5 apps is an interactive plotter for climate annual indices. There's a whole lot of annual data from which you can click to put on a plot. There's an elaborate arrangement for handling different units, anomaly bases etc. You can slide curves around in the plot, and fit various types of curve by OLS regression.
In these respects it's a bit like WoodForTrees. The main difference is that it is client side - the code and data sit on your machine. This adds speed and on screen flexibility, but makes some facilities like Fourier analysis more difficult, and limits the amount of data that can be used (which is why it is annual only).
I'll give detailed instructions below the plot. To try it, just click on a data set. For the moment, there is a restriction to 7 curves with up to 3 sets of units. You can click on the pink and blue axis bars to move plots around. For more details, you can click with Ctrl pressed on any functional button to get info about it in the window bottom right.
I've added some new utilities. You can add a legend; just click on the plot area where you would like the legend to be. Clicking elsewhere will move it; clicking within the canvas but outside the plot area will make it vanish.
Below the graph, there is a long URL in small writing. If you copy that, it will reproduce the current graphs in a different browser (for linking)
There is also a window bottom left in which you can write your own title.

|
|
| Information: |
Sunday, March 11, 2012
February GISS up 0.05°C - comparison
February 2012 temperatures down 0.05°C
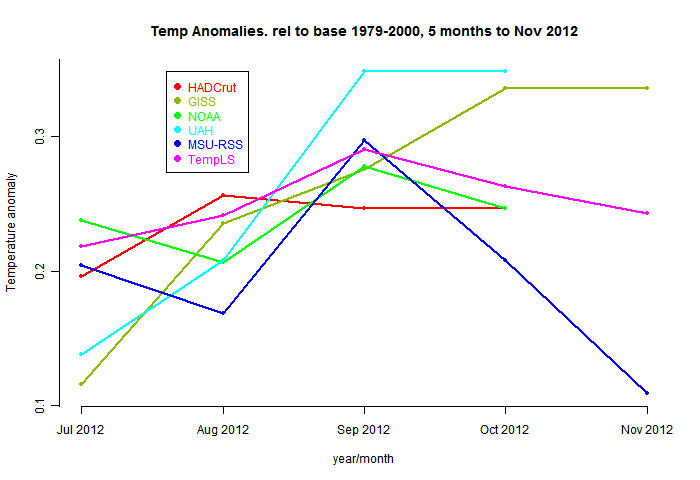
The TempLS analysis, based on GHCNV3 land temperatures and the ERSST sea temps, showed a monthly average of 0.18°C, down from 0.23 °C in January. As last month, this is in line with satellite LT trends. There are more details at the latest temperature data page.Below is the graph (lat/lon) of temperature distribution for February.

This is done with the GISS colors and temperature intervals, and as usual I'll post a comparison when GISS comes out.
And here, from the data page, is the plot of the major indices for the last four months:
Friday, March 9, 2012
Feb TempLS temperature down 0.05°C
February 2012 temperatures down 0.05°C
The TempLS analysis, based on GHCNV3 land temperatures and the ERSST sea temps, showed a monthly average of 0.18°C, down from 0.23 °C in January. As last month, this is in line with satellite LT trends. There are more details at the latest temperature data page.Below is the graph (lat/lon) of temperature distribution for February.
This is done with the GISS colors and temperature intervals, and as usual I'll post a comparison when GISS comes out.
And here, from the data page, is the plot of the major indices for the last four months:
Wednesday, March 7, 2012
Lindzen's misrepresentation at House of Commons
Prof Lindzen gave a presentation at the House of Commons in London on 22 February. Judith Curry ran a post that now has over 1200 comments.
Real Climate has noted what I think is quite a shocking misrepresentation. It is in this slide:

It's yet another in the series of claims that someone is "manipulating the record". That's a heavy accusation. But as RC I think convincingly demonstrates, this is not a comparison of two versions of the same index. It is a comparison of the land only, met stations index “GLB.Ts.txt” in 2012 with the land and ocean index “GLB.Ts+dSST.txt” in 2008. And, as is well known, the land index has a higher slope. As they show, the land ocean index properly compared has changed very little over that period.
So did Lindzen just make a mistake? Well, as Hank Roberts has shown, it looks awfully like he just lifted it, without attribution (but that's not to say without permission) from the JunkScience blog, Feb 7th.

Update: Here is my own plot of the difference between current values of GISS Ts (land only) and GISS Ts+dSST (land/ocean):


Real Climate has noted what I think is quite a shocking misrepresentation. It is in this slide:
It's yet another in the series of claims that someone is "manipulating the record". That's a heavy accusation. But as RC I think convincingly demonstrates, this is not a comparison of two versions of the same index. It is a comparison of the land only, met stations index “GLB.Ts.txt” in 2012 with the land and ocean index “GLB.Ts+dSST.txt” in 2008. And, as is well known, the land index has a higher slope. As they show, the land ocean index properly compared has changed very little over that period.
{kind=link}
So did Lindzen just make a mistake? Well, as Hank Roberts has shown, it looks awfully like he just lifted it, without attribution (but that's not to say without permission) from the JunkScience blog, Feb 7th.
Update: Here is my own plot of the difference between current values of GISS Ts (land only) and GISS Ts+dSST (land/ocean):
Update. Carrick suggested puting the plot of the diff between 2008 and 2012 LOTI on the same plot. I've done that. Following Gavin, I used the wayback Oct 2008 version, and showed the plots and trends to end 2007.
So for the 2012 cases, I got a slightly different trend to the above, which was for the period 1880-2011. The trend now is 0.114 °C/century, and the trend difference between LOTI 2009 and now is -0.00216 °C/century. This is slightly different to Gavin's, and has negative sign. I don't know why, but in absolute magnitude both trends are small. It's possible my wayback version is different from Gavin's.
Here's the plot. In the background (faint) is the initial plot, though cut at end 2007. In darker color is the diff in GISS LOTI (land/ocean) between the Oct 2008 version and now.